Machine learning
[설치]. 리눅스 환경에서 Anaconda 설치하기
리눅스의 경우 일반적으로 터미널에서 진행한다고 가정하고 설치 설치파일 다운로드 curl -0 https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh 다운로드가 완료되면 bash 명령어를 통해 설치파일 실행 bash Anaconda3-5.0.1-Linux-x86_64.sh 라이센스 동의를 구하는 메시지가 나오면 'yes' 입력 Do you approve the license terms? [yes|no] 아니콘다 설치 경로를 선택하는 메세지 -> 엔터눌러서 기본경로에 설치 Anaconda3 will now be installed into this location: /home/username/anaconda3 설치가 완료되면 아나콘다에 대한 경로를..
[데이터 전처리]. tqdm pandas , apply & map progress_bar 생성
tqdm 은 for 문을 처리할때 진행률을 표시해주는 파이썬 라이브러리이다. 하지만 pandas 에서 열전체의 함수를 매기는 map 이나 데이터프레임 전체에 함수를 매기는 apply 의 경우 많은 데이터의 실행을 했을 때 진행률을 알 수 없고 주피터에서 * 표시만 계속 쳐다볼뿐이다. 그래서 pandas 의 map 함수와 apply 함수의 진행률을 볼 수 있는 방법을 공유한다. apply import pandas as pd import numpy as np from tqdm import tqdm # from tqdm.auto import tqdm # for notebooks df = pd.DataFrame(np.random.randint(0, int(1e8), (10000, 1000))) # Create ..

[기계 학습]. SGD 와 mini batch ( 최적화 기법 )
Batch size 의 개념 3명의 학생이 있고 100개의 문제를 주어졌을 때 여러가지 상황이 있다. 1번 학생 ( Batch size == 100 ) : Full-batch 1번 학생은 100개의 문제를 다 풀고 난 뒤 정답을 확인하고 수학문제 정답률을 증가시킨다. 2번 학생 ( Batch size == 10 ) : Mini-batch 2번 학생은 100개의 문제중 10개의 문제를 보고 답안지를 보고 정답률은 향상시키고 또 다시 10개의 문제를 보고 정답률을 향상시킨다 ( 10회 반복 ) 3번 학생 ( Batch size == 1 ) : SGD 3번 학생은 100개의 문제를 하나 풀고 정답보고 정답률 향상 시키고 , 하나 풀고 정답보고 ....(100회 반복) 즉 문제하나를 풀 때마다 수정 , 개선 방..
[기계 학습] sklearn.pipeline 파이프 라인
전통적인 머신러닝을 사용하다 보면 전처리 작업을 한 번에 하고 난 뒤 모델을 돌릴 때도 있지만 모델 별로 전처리를 다르게 해주거나 또는 다른 전처리방법을 실험해보기 위해서 전처리를 복잡하게 반복할 때가 있다. 하지만 sklearn에 pipeline은 그 반복적인 작업을 쉽게 할 수 있게 해준다. pipeline은 통로라는 뜻으로 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 가리킨다. 파이프라인을 사용하면 데이터 사전 처리 및 분류의 모든 단계를 포함하는 단일 개체를 만들 수 있다. train과 test 데이터 손실을 피할 수 있다. 교차 검증 및 기타 모델 선택 유형을 쉽게 만든다. 재현성 증가 설명이 어렵지만 예제를 보면 쉽게 이해할 수 있다. from sklear..
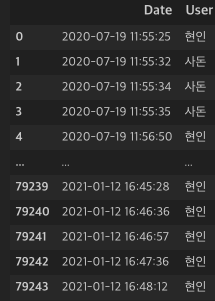
[데이터 전처리]. 날짜 데이터 전처리
우리는 위처럼 시간데이터를 DateTime 형태로 받아 들이게 되는 데 이것을 문자열로 나눠서 정제하는 방법도 있지만 쉽게 파생변수로 만들어주는 방법이 있다. tt['Date'] = pd.to_datetime(tt['Date']) tt['Wday'] = tt['Date'].dt.day_name() tt['yyyymm'] = tt['Date'].dt.strftime('%Y%m') tt['yyyy'] = tt['Date'].dt.strftime('%Y') tt['mm'] = tt['Date'].dt.strftime('%m') tt['dd'] = tt['Date'].dt.strftime('%d') tt['hh'] = tt['Date'].dt.strftime('%H') 이렇게 해주면 알아서 분리 된다. 끝

[기계학습] Stacking (스태킹)
스테킹은 앙상블 기법중 하나로 정확도를 극한으로 끌어올릴 때 주로 사용된다.우리는 분류 모델을 돌릴 때 여러가지 모델을 사용한다. Logistic , KNN , Random Forest , Boosting 모델 등 이 모델들은 정확도가 다 다르고 보통 여기서 가장 좋은 모델을 채택하게 된다. 하지만 이 모든 모델을 합치면 어떨까? 여기서 합친다는 뜻은 모델들이 각각 유권자가 된다는 것으로 이해하면 된다. 모델들이 예측한 결과만 합쳐서 새로운 테이블을 만들어 내는 것이다.LogisticKNNRandom ForestLightGBMXGBoost실제값111011011101111111001000101111임의로 만들어 낸 예시 이지만모델들의 예측결과를 이렇게 테이블 형테로 가져오고 이 상태에서 다시 예측을 진행한..
[기계학습] . Imbalanced Data ( 불균형 데이터 ) - SMOTE
분류 문제를 해결할 때 데이터의 분포를 가장 먼저 확인합니다. 이럴 때 데이터가 너무 한쪽으로 치우친 불균형 데이터를 종종 접하게 됩니다. 이런 불균형 데이터를 가지고 학습을 시키면 과적합 문제가 발생할 가능성이 높습니다. 불균형 데이터를 균형있게 바꿔주는 방법을 알아보자. 방법은 데이터를 샘플링 하는 방법입니다. 말 그대로 샘플을 만드는 방법입니다. 1. Under Sampling 적은 데이터를 기준으로 균형을 맞추는 방법입니다. 장점 : 유의미한 데이터만 남길 수 있습니다. 단점 : 정보가 유실되는 문제가 생길 수 있습니다. 2. Over Sampling 많은 데이터를 기준으로 균형을 맞추는 방법입니다. 장점 : 정보의 손실을 막을 수 있습니다. 단점 : 여러 유형의 관측치를 다수 추가 -> 오버 피..
[기계학습]. 정형데이터에서 시도해볼 수 있는 전략들
오늘은 정형데이터에서 정확도를 높히기 위해 시도해 볼 수 있는 전략들을 아는 만큼 적어보려고 한다. 정형 데이터에 대해 시도 해봤던 것들. 전처리 부분 1. 결측치 처리 결측치는 데이터에 따라 빈번하게 나타나는데 결측치를 처리하는 방법은 다양하다. - 그냥 제거하는 방법 - 중위값 , 평균값으로 대체 하는 방법 - 결측치 자체를 Y 데이터로 해서 나머지로 예측하는 방법 경험상 예측하는 방법이 성능이 좋았던 기억이 있고 그때는 Gradient Boosting 모델을 사용했다. 2. 파생 변수 생성 데이터의 열 정보를 꼼꼼히 살펴보고 파생변수로 만들 수 있는 것이 있다면 추가해주는 것이 좋다. 예측에 있어서 열이 너무없다면 많이 늘리는 것이 중요하다. 특성교차 방법 사용 변수 두개를 곱하거나 , 원 핫 벡터..
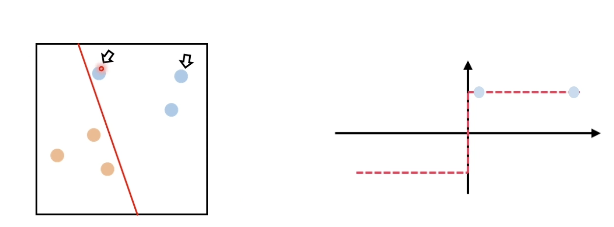
[Deep Learning] Activation Function ( 활성화 함수 ) - 2. 종류
전 포스팅에서 활성화 함수의 사용 이유에 대해서 알아보았습니다. 이번엔 활성화 함수의 종류에 대해서 알아보겠습니다. 1. Sign function sign 함수를 활성화 함수를 사용할 경우 기준 점을 기준으로 0과 1로만 분류하기 때문에 결정 경계로 부터 거리를 신경쓰지 않습니다. 즉, 결정경계와 멀리 떨어져 있든 가깝던 1과 0으로 표기 하기 때문이죠. (분류가 잘 되지 않음) 그래서 이런 경계를 부드럽게 표현하여 거리의 정도를 나타내는 함수를 사용하게됩니다. 2. Tanh 함수 Tanh 함수는 값이 작아질 수록 -1, 거질 수록 1 에 수렴 가장 중요한 특징은 모든 점에서 미분이 가능 (미분이 가능하다 == 기울기가 존재한다. ) 3. sigmoid 함수 sigmoid 함수는 값이 작아질 수록 0 커..
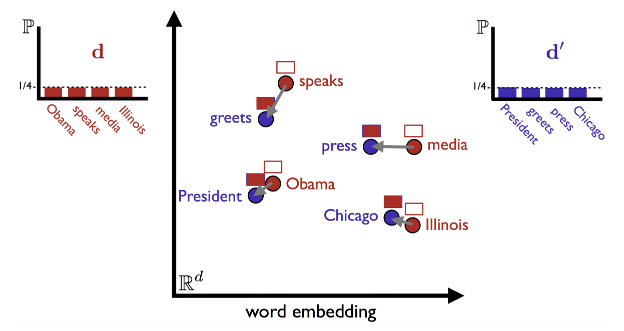
[NLP] 수능 영어지문을 풀어주는 인공지능 (WMD)
이번에 진행한 프로젝트는 수능 영어 지문 중에서 주제를 찾는 문제를 풀어보는 인공지능을 구현해 보겠습니다. from nltk import download from nltk import word_tokenize from nltk.corpus import stopwords from nltk.stem.lancaster import LancasterStemmer from nltk.stem import WordNetLemmatizer import nltk download('stopwords') stop_words = stopwords.words('english') import pandas as pd import numpy as np 먼저 기본적인 영어 NLP 를 처리해주는 패키지를 사용했습니다. def _prep..