![[기계학습] . Imbalanced Data ( 불균형 데이터 ) - SMOTE](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdGXoRC%2FbtqVyVxnYuX%2FAAAAAAAAAAAAAAAAAAAAAOtwpo7fg48jVGWVIcbkt_Kw6bS3jSFCOzhm1DnIyF6o%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DkpzPCan%252BhNk1hjn8UY%252F0lIkUTQM%253D)
분류 문제를 해결할 때 데이터의 분포를 가장 먼저 확인합니다.
이럴 때 데이터가 너무 한쪽으로 치우친 불균형 데이터를 종종 접하게 됩니다.
이런 불균형 데이터를 가지고 학습을 시키면 과적합 문제가 발생할 가능성이 높습니다.
불균형 데이터를 균형있게 바꿔주는 방법을 알아보자.
방법은 데이터를 샘플링 하는 방법입니다.
말 그대로 샘플을 만드는 방법입니다.
1. Under Sampling
적은 데이터를 기준으로 균형을 맞추는 방법입니다.

장점 : 유의미한 데이터만 남길 수 있습니다.
단점 : 정보가 유실되는 문제가 생길 수 있습니다.
2. Over Sampling
많은 데이터를 기준으로 균형을 맞추는 방법입니다.
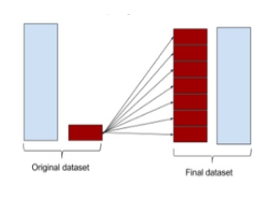
장점 : 정보의 손실을 막을 수 있습니다.
단점 : 여러 유형의 관측치를 다수 추가 -> 오버 피팅 야기
상황에 따라 다르겠지만 대부분은 정보의 손실을 막는 Over Sampling을 많이 사용합니다.
다양한 샘플링 방법을 시도했지만
그 중 가장 성능이 좋았던 SMOTE 방법을 알아보겠습니다.
먼저 샘플링 전 데이터는 총 7081개의 데이터 중 5968 : 1 , 1113 : 0입니다. (불균형한 데이터)
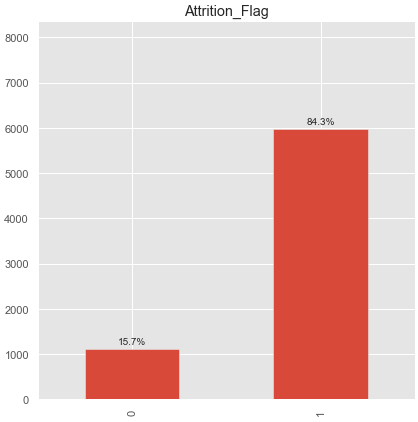
데이터 전처리를 다 진행하고 train , test 도 다 나눈 상태에서 진행합니다.
from imblearn.over_sampling import SMOTE해당 패키지를 임포트합니다.
x_train, x_test, y_train, y_test = train_test_split(x_scaled,y_data,test_size=0.3,random_state=0)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)(4956, 32)
(2125, 32)
(4956, 1)
(2125, 1)
sm = SMOTE(sampling_strategy='auto', random_state=0)
x_smote, y_smote = sm.fit_resample(x_train,y_train)* sampling_strategy 속성으로 바람직한 비율을 직접 지정할 수 있습니다. 0,1 , 0,5 , default = 'auto'
이렇게 진행해주면 알아서 샘플링을 진행합니다.
결과를 출력해 보겠습니다.
print('After SMOTE OverSampling, the shape of x: {}'.format(x_smote.shape))
print('After SMOTE OverSampling, the shape of y: {} \n'.format(y_smote.shape))
print("After SMOTE OverSampling, counts of label '1': {}".format(y_smote.sum()))
print("After SMOTE OverSampling, counts of label '0': {}".format(len(y_smote)-y_smote.sum()))
이런 불균형 데이터에 대해서 SMOTE는 먼저 trainX를 8302개로 만들었고
1과 0의 비율을 50 : 50으로 4151개씩 반반으로 나눴습니다.

SMOTE로 데이터 불균형 해결하기
현실 세계의 데이터는 생각보다 이상적이지 않다.
john-analyst.medium.com
imbalanced-learn.org/stable/generated/imblearn.over_sampling.SMOTE.html
imblearn.over_sampling.SMOTE — imbalanced-learn 0.7.0 documentation
© Copyright 2016 - 2017, G. Lemaitre, F. Nogueira, D. Oliveira, C. Aridas
imbalanced-learn.org
'Machine learning' 카테고리의 다른 글
| [데이터 전처리]. 날짜 데이터 전처리 (0) | 2021.02.09 |
|---|---|
| [기계학습] Stacking (스태킹) (0) | 2021.02.03 |
| [기계학습]. 정형데이터에서 시도해볼 수 있는 전략들 (0) | 2021.02.01 |
| [기계학습] Kernel Support Vector Machines ( KSVMs , 커널 서포트 벡터 머신) (0) | 2021.01.12 |
| [데이터 전처리]. pandas Dataframe 중복된 값 제거하기 (0) | 2020.12.04 |