Data Science/ADsP
[ADsP]3과목 - 4장.연관분석
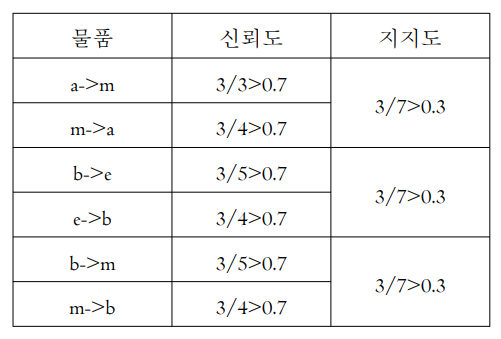
연관분석 기업의 마케팅분야에 많이 활용 데이터의 거래정보(트렌젝션)를 연관석 규칙을 이용하여 장바구니 분석이라고함. 활용 매장 내 상품 진열 묶음 판매 쿠폰발행 교차판매 지지도 support(A->B) 의미는 IF A 구매 THEN B 도 구매 A와 B의 순서가 바뀌어도 상관이없음 신뢰도 신뢰도(A->B): 물품 A를 구매했다는 조건하에 물품 B를 구매확률 =P(B|A) 조건부 확률 신뢰도가 50% 이라는 의미는 “A를 구매한 거래 가운데 50% B도 구매” Confidence(A->B) ≠ Confidence(B->A) 순서를 바꾸게 되면 같지 않다. 향상도 향상도는(A->B) 전체에서 B가 거래된 비율과 / A가 구매되었다는가정하에 B가 구매된 비율사이의 비율 lift(A->B)=lift(B->A) ..
[ADsP]3과목 - 4장.군집분석,k평균군집,혼합분포군집,SOM(자기조직화지도)
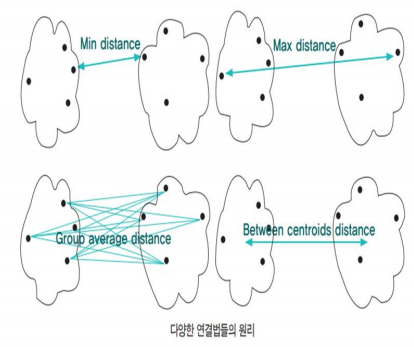
군집분석 군집내는 동질적이게 군집외는 이질적이게 하는 것 분석대상 상호관련성에 의해 설 동질적인 집단으로 그룹핑 사전에 집단이 모르는 자료를 유사한 것들끼리 분류하여 군집 비지도학습(목표변수 없음) 계층적 군집분석 유사한 개체를 묶어 나가는 과정을 반복하여 원하는 갯수의 군집을 형성 응집형(병합방법) : Bottom-up 하나의 군집이 남을 때 까지 순차적으로 군집들을 병합 (계층적 군집분석에는 주로 병합 방법이 쓰임) 분리형(분리방법) : Top - down 하나의 군집에서 n개 군집으로 분리 군집 방법 두 군집 사이의 거리 단일 연결법 (single linkage) 한 군집의 점과 다른 군집의 점 사이의 가장 짧은 거리. ( 사슬 모양이 생길 수 있다.) 완전 연결법 (complete linkage)..

[ADsP]3과목 - 4장.의사결정나무, 앙상블 모형
의사결정나무 구성 의사결정나무 모형 구축 Split(가지 분할) -> 나무의 가지를 생성 Stopping rule(정지규칙) -> 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디 (기준) 최대나무의 깊이 , 자식마디의 최소 관측치 수 , 카이제곱 통계량 , 지니지수, 엔트로피 지수 Pruning(가지치기) -> 생성된 가지를 잘라내어 단순화 끝마디가 너무 많으면 (Overfitting) (기준) 분류된 관측치의 비율 또는 MSE 의사결정나무 분리기준 목표변수의 분포를 구별하는 정도 : 순수도 or 불순도 순수도 : 목표변수 특정 범주에 개체들이 포함되어 있는 정도 부모마디의 순수도에 비해서 자식마디들의 순수도가 증가하도록 자식마디를 형성함. 분류기준 이산형 목표변수(분류나무) 각 범주에 속하는 빈도에..

[ADsP]3과목 - 4장.로지스틱회귀분석,신경망모형
로지스틱 회귀분석 종속변수가 "성공 또는 실패" , "흡연 또는 비흡연" 이항변수로 되어 있을 때 종속변수와 독립변수간의 관계식을 두 집단이상으로 분류하고자 할 때 사용되는 분석기법 일반선형 회귀분석 로지스틱 회귀분석 종속변수 연속형변수 이산형변수 모형 탐색 방법 최소자승법 최대우도법, 가중최소자승법 모형 검정 F-test, t-test X^2test 활용예시) TV 홈소핑 반품에 영향을 미치는 요인 변수 : 독립변수(소득,학력,성별,거주지,구매금액) , 종속변수(반품유무) 결과 : 20-30대의 젊은 여성, 고학력, 고소득일수록 반품률이 높음 로지스틱 회귀모형 종속변수가 두 가지 범주(Y or N)를 나타내는 이항변수일 경우 기댓값은 확률을 의미하므로 0~1사이의 값을 가지는 곡선형태의 모형이다. 부호..

[ADsP]3과목 - 4장.데이터마이닝,모형평가
데이터 마이닝 자동화(Automated) 숨겨진(Hidden) 예측가능(Predictive) 데이터마이닝 표본조사/실험에서 모형에 대한 전제조건이 필요하지 않음. 모집단의 전체자료를 이용하여 정보추출 대용량 자료 데이터마이닝 기법을 사용하기 위해 데이터웨어하우스가 필요하다. SQL 2019년 1월에 50만원 이상 구매 고객 OLAP 2019년 1월에 50만원 이상 구매,여자,미혼,년 소득이 5천만원 이상 Mining 미혼남,서울거주,년소득 3천만원,취미가 여행인 고객의 신용불량여부 예측 지도학습 종류 인공신경망 의사결정나무 판별분석 선형회귀분석 로지스틱 회귀분석 사례기반추론 지도학습은 명확한 입력변수와 목표변수가 존재하고 분류와 예측이 있다. 비지도학습 종류 OLAP 연관성규칙 군집분석 인자분석 주성분분..

[ADsP]3과목 - 3장.상관분석 및 다차원분석, 주성분분석,시계열 예측
상관분석 두 수치형 변수간의 선형성의 정도, 관련성을 파악하는 방법이다. 피어슨의 상관계수, 스피어만의 상관계수 , 켄달의 순위상관계수 등이 있다. 상관분석은 두 변수의 선형성의 정도를 알아보고 인과관계를 의미하는 것은 아니다. 회귀계수는 인과관계를 알아보는 것이다. 밑의 3, 4 번 그림은 상관계수가 0 일때 나타난다. 상관계수의 범위 -1

[ADsP]3과목 - 2장.정규성 검정,단순회귀,결정계수,다중공선성,설명변수 선택
정규성 검정 Q-Q plot 그래프를 그려서 정규성 가정이 만족되는지 시각적으로 확인하는 방법이다. 대각선 참조선을 따라서 값들이 분포하게 되면 정규성을 만족한다고 할 수 있다. 한쪽으로 치우치면 정규성 가정에 위배되었다고 볼 수 있다. Shapiro-Wilk test( 샤피로 - 윌크 검정 ) 오차항이 정규분포를 따르는지 알아보는 검정, 회귀분석에서 모든독립변수에 대해서 종속변수가 정규분포를 따르는지 알아보는 방법이다. 귀무가설은 , '정규분포를 따른다' p-value 가 0.05보다 크면 정규성을 가정하게 된다. Kolmogorov-Smirnov test(콜모고로프-스미노프 검정) 자료의 평균/표준편차와 히스토그램을 표준정규분포와 비교하여 적합도를 검정한다. 샤피로와 마찬가지로 p-value가 0.0..

[ADsP]3과목 - 2장.점추정과 구간추정 , 가설검정 , 비모수 검정
추정과 구간 추정 점추정 모수를 특정한 수치로 표현하는 것 추정 추정치 : 모수를 추정하기 위해 선택된 표본을 대상으로 구체적으로 도출된 통계량 추정량 : 표본에서 관찰된 값으로 추정치를 계산하기 위한 도출 함수 바람직한 점 추정량의 조건 불편성 : 추정량이 모수와 같아야 한다. 일치성 : 표본의 크기가 모집단 규모에 근접해야 한다. 유효성 : 추정량의 분산이 최소값이어야 한다. 충분성 : 표본이 모집단의 대표성을 가져야 한다. 구간추정 모수를 최소값과 최대값의 범위로 추정하는 것 일정한 크기의 신뢰수준으로 모수가 특정한 구간에 있을 것 이라고 선언 구해진 구간을 신뢰구간이라고한다. 표본의 크기가 커질 수록 구간이 좁아진다. ( 정보가 많을수록 추정량이 더 정밀하다는 것을 의미 ) 신뢰구간 95% 라는 ..

[ADsP]3과목 - 2장.확률 및 확률분포 , 표본의 분포
통계학 : 수량적인 비교를 기초로 많은 사실을 관찰하고 분석하는 방법을 연구하는 학문 신뢰성 확보 , 의사결정에 근거, 문제해결을 위한 원인 파악 기술통계 : 표본에 대한 분석 결과의 각종 수치들을 활용하여 집단의 특성을 설명 자료의 요약 , EDA의 시각화 추론통계 : 표본을 활용하여 모집단의 특성을 나타내는 것 추정 모수 vs 통계량 모수(전수조사) 모수(Parameter) : 모집단을 분석하여 얻어지는 결과 수치 모평균, 모분산 , 모표준편차 , 모비율 통계량(표본조사) 통계량(Statistic) : 표본을 분석하여 얻어지는 결과 수치(통계치) 표본평균, 표본분산 .. 표본추출방법 확률적 표본추출 단순 무작위 추출 난수추출 계통 추출법 일정한 n개의 간격으로 표본추출 ,인터발 군집(집락)추출 내부 ..

[ADsP]3과목 - 1장. reshape패키지,sqldf,data.table함수 , 결측값 처리와 이상값 검색
reshape2 패키지에는 melt() 와 cast() 만을 사용하여 데이터를 재구성하거나 유연하게 만든다. 요약하기 편하고 시각화하기 편하게만듬. melt( data , id , vars, na.rm = FALSE ) 여러 변수로 구성된 데이터를 데이터id , variable , value 형태로 재구성한다. id.vars : 식별컬럼 variable : 측정변수 value : 측정값 na.rm = FALSE : NA인 행을 결과에 포함시킬지 여부. cast( data , id변수~variable변수, formula) melt()된 데이터를 여러 column 으로 변환한다. library(reshape2) > data("airquality") > names(airquality) head(airquali..