![[ADsP]3과목 - 1장. reshape패키지,sqldf,data.table함수 , 결측값 처리와 이상값 검색](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FTkJkw%2FbtqEn8slw3s%2FAAAAAAAAAAAAAAAAAAAAAOyh1iAiWIO3HsB29XORu46_kjNpw64H3KpPEmcUun-o%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DsxYLE6ctTKDpTSELrdRLMxHHiXY%253D)
728x90
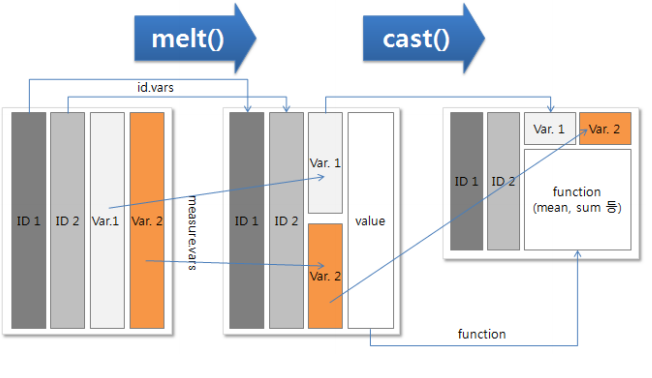
reshape2 패키지에는
melt() 와 cast() 만을 사용하여 데이터를 재구성하거나 유연하게 만든다.
요약하기 편하고 시각화하기 편하게만듬.
melt( data , id , vars, na.rm = FALSE )
여러 변수로 구성된 데이터를 데이터id , variable , value 형태로 재구성한다.
- id.vars : 식별컬럼
- variable : 측정변수
- value : 측정값
- na.rm = FALSE : NA인 행을 결과에 포함시킬지 여부.
cast( data , id변수~variable변수, formula)
- melt()된 데이터를 여러 column 으로 변환한다.
| library(reshape2) > data("airquality") > names(airquality) <- tolower(names(airquality) > head(airquality) ozone solar.r wind temp month day 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 5 NA NA 14.3 56 5 5 6 28 NA 14.9 66 5 6 #melt() aql <-melt(airquality,id.vars = c("month","day")) head(aql) month day variable value 1 5 1 ozone 41 2 5 2 ozone 36 3 5 3 ozone 12 4 5 4 ozone 18 5 5 5 ozone NA 6 5 6 ozone 28 #cast() dcast(aql , month ~ variable ) #dcast는 cast를 d ( dataframe ) 으로 반환하겠다는 뜻 reshape2패키지에만 있음 month ozone solar.r wind temp 1 5 31 31 31 31 2 6 30 30 30 30 3 7 31 31 31 31 4 8 31 31 31 31 5 9 30 30 30 30 # 식별자가 하나일 때 자동으로 length()를 적용해 같은셀에 모인 행의 개수를 센다. dcast(sql,month ~ variable, mean , na.rm = TRUE) # sum , mean, range 구할 수 있다. month ozone solar.r wind temp 1 5 23. 61538 181.2963 11.622581 65.54839 2 6 29. 44444 190.1667 10.266667 79.10000 3 7 59. 11538 216.4839 8.941935 83.90323 4 8 59. 96154 171.8571 8.793548 83.96774 5 9 31. 44828 167.4333 10.180000 76.90000 |
sqldf를 이용한 데이터 분석
- SQL문을 이용한 데이터 분석
- 데이터를 불러올 때 select를 이용
- sqldf("select*from iris")
- sqldf("select*from iris limit 6 ) # head()랑 같음
데이터테이블
- 데이터프레임과 비슷하지만 반환값들이 다른점들이있음.
- 특정 컬럼을 키값으로 색인을 지정한 후 데이터처리를 하기 때문에 데이터프레임보다 빠름
- 행 번호가 콜론 형태로 구분
- tables() 를 통해서 여태 만들어논 데이터테이블 목록확인
- 키값을 지정해 해당 값으로 접근 , 함수는 setKey(데이터테이블객체명,정렬할 컴럼) 형식
| setkey(iris_table,Species) # Species 키값 부여 tables() NAME NROW NCOL MB COLS KEY 1: iris_table 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species iris_table["setosa"] 키값을 이용해 빠른 검색이 가능 |
결측값 확인 및 처리
is.na()
- NA값을 조사해 논리값으로 반환 ( NA=TRUE)
|
y<-c(1,2,3,NA) is.na(y) |
sum() 함수나 mean()함수를 통해서도 확인 가능
결측값이 있을 때 어떠한 산수를 해도 NA(결측값이 나오기때문)
하지만 na.rm = TRUE 옵션을 설정하면 산수가능
complete.cases()
- NA값을 조사해 논리값으로 반환 ( NA = FALSE ) is.na() 와 반대
특정값을 결측 처리
|
iris[iris==4.0] <- NA |
데이터프레임에서 결측값만 선택 또는 삭제
| iris_na <- iris iris_na[c(10,20,30),3] <- NA #iris 3번째 변수 Patal.Length의 10,20,30번째 행을 NA로 바꿔라(결측처리) iris_na[!complete.cases(iris_na),] # 결측값이 있는 행만 추출 |
na.omit()
- NA가 있는 행 전체 삭제
결측값의 대치법
- 결측/무응답을 가진 자료를 무시하지 않고 분석할 수 있는 통계 방법론의 하나인 대치법
| 완전히 응답한 개체분석 | 불완전 자료는 모두 무시하고 완전하게 관측된 자료만으로 표준적 통계기법에 의해 분석하는방법 |
| 평균대치법 | 관측 또는 실험되어 얻어진 자료의 적절한 평균값으로 결측값 대치 |
| 단순확률 대치법 | 평균대치법에서 추정량 표준오차의 과소 추정문제를 보완하고자 고안된 방법, 변수들이 비슷한 집단에서 임의의 한 개체를 선택해서 대채 |
| 다중대치법 | 대치(가상의 완전데이터 생성) -> 분석(가상자료의 추정량과 분산을 계산) -> 결합(생성데이터와 추정량 결합하여 통계적 추론) |
이상값 검색
- 이상값은 의도하지 않게 잘못 입력된 경우(bad data)
- 의도하지 않게 입력됐으나 분석 목적에 부합되지 않아 제거해야 하는 경우(bad data)
- 의도되지 않은 현상이지만 분석에 포함해야 하는 경우(이상값)
- 의도된 이상값 (아웃라이어) ---> 사기
이상값이라는 절대적 기준은 없고 밑의 조건으로 일반적으로 이상치를 판단한다.
- 관련된 알고리즘 ESD(평균으로부터 3*표준편차 밖의 값을 이상치)
- 상자그림 (Boxplot) IQR*1.5 밖의 값을 이상치로 구분
- 일반적으로 summary() 평균과 중앙값과 boxplot 이용
결과적으로 이상값과 분석 대상이 될 수 있어 무조건 삭제하는 건 옳지않다.
Outlier 패키지 활용하기
| data(iris) attach(iris) iris2<-subset(iris,select=c(1,5)) #Sepal.Length와 Species 추출 iris1<-subset(iris,select="Sepal.Length") #Sepal.Length 추출 outlier(iris1) #평균과 가장 차이가 많이 나는 값 출력 Sepal.Length 7.9 outlier(iris1,opposite = TRUE ) #반대방향으로 가장 차이가 많이 나는 값 출력 Sepal.Length 4.3 |
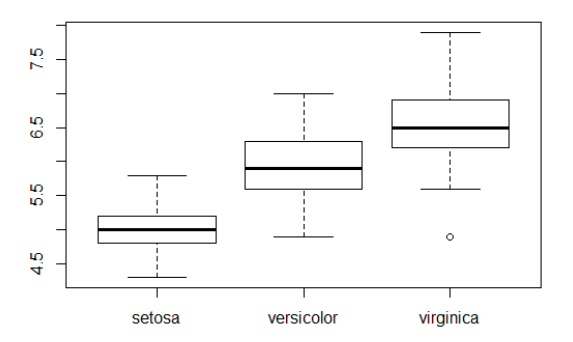
상자그림으로 확인
| plot(Species, Sepal.Length) # x 축이 범주형이기때문에 상자그림 생성 |
반응형
'Data Science > ADsP' 카테고리의 다른 글
| [ADsP]3과목 - 2장.점추정과 구간추정 , 가설검정 , 비모수 검정 (0) | 2020.05.25 |
|---|---|
| [ADsP]3과목 - 2장.확률 및 확률분포 , 표본의 분포 (0) | 2020.05.25 |
| [ADsP]3과목 - 1장. 데이터마트와 apply함수,plyr 패키지 (0) | 2020.05.23 |
| [ADsP]3과목 - 1장. R 기초(R의 기초통계, 데이터 핸들링,R그래프의 이해) (0) | 2020.05.22 |
| [ADsP] 2과목 - 2장. 분석 마스터 플랜 (0) | 2020.05.20 |