![[ADsP]3과목 - 1장. 데이터마트와 apply함수,plyr 패키지](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbfqbIC%2FbtqEljBr4Ng%2FAAAAAAAAAAAAAAAAAAAAADER9hHhA_GsPMUA6Nz9vDI-QxPeV7MiSWE3Wf3Aqs0K%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DvLjvM30U%252F16uvSaFYzuK2LPuF%252FY%253D)
데이터 가공
데이터웨어하우스(DW)와 데이터마트(DM)
DW는 물류창고라고한다면 DM는 대형마트이다.
데이터 웨어하우스는 최적화되어 있지 않고 비효율적 배치라면
데이터마트는 사용하기 쉽게 시스템에 최적화됨.
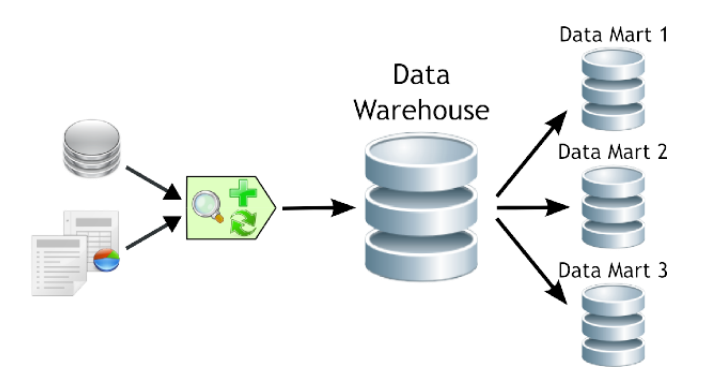
DW에서 DM 로 변환하기 위해서
여러가지 패키지들이 필요하다.
|
reshape 패키지 , apply 함수들 , plyr 패키지 dplyr 패키지 |
plyr 패키지
apply 함수에 기반해 데이터와 변수를 동시해 배열로 치환.
가로 세로로 되어있는 2차원 데이터의 행의합 열의합의 각각 요약치들을 나타낼 수 있는 함수들.
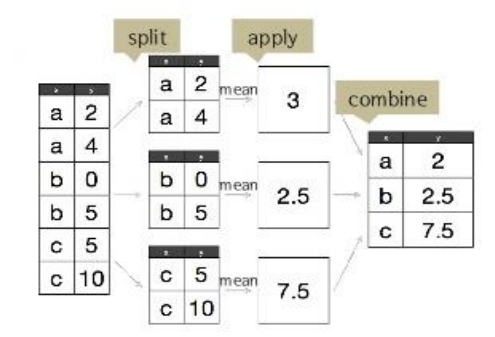
split -> apply -> combine 기능 제공
데이터분할 -> 함수를 적용 -> 재결합
apply 함수들 ( lapply , sapply , tapply )
apply(x,margin,fun)
- x에 fun을 margin 방향으로 적용 결과를 벡터 , 배열 , 리스트 반환
- margin 1 이면 = '행' , margin 2 이면 = "열", c(1,2) 행, 열방향 의미
| a <- matrix(1:6,ncol=2) [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 apply(a,1,sum) #행렬의 각 행의 합 ( 1+4 , 2+5 , 3+6) [1] 5 7 9 |
| #iris dataset 중 factor열인 Species 제외한 데이터프레임만 가져와 열의 합을 구함 apply(iris[,-5],2,sum) Sepal.Length Sepal.Width Petal.Length Petal.Width 876.5 458.6 563.7 179.9 #colSums() 통해서도 같은 값을 구할수 있다. > colSums(iris[,-5]) Sepal.Length Sepal.Width Petal.Length Petal.Width 876.5 458.6 563.7 179.9 |
R에 apply 기능을 하는 함수들 : 각행과 열의 합과 평균의 함수는 colSums(),colMeans(),rowSums(),rowMeans()
lapply(x, 함수)
- x 는 벡터 또는 리스트, 데이터 프레임 적용해서 리스트로 반환
| x <- list(c(1:10),c(1,3,5,7,9),c(4,5,6,7,8,9,10)) x [[1]] [1] 1 2 3 4 5 6 7 8 9 10 [[2]] [1] 1 3 5 7 9 [[3]] [1] 4 5 6 7 8 9 10 lapply(x,mean) [[1]] [1] 5.5 [[2]] [1] 5 [[3]] [1] 7 |
sapply(x, 함수)
- sapply()는 lapply()와 유사하지만 리스트대신 행렬, 벡터 등으로 결과를 반환하는 함수이다.
- 입력으로는 벡터, 리스트 , 데이터 프레임등이 쓰일 수 있다.
| sapply(x,mean) [1] 5.5 5.0 7.0 #벡터로 반환 |
tapply(데이터, 색인 , 함수)
- 그룹별 처리를 위한 apply 함수
- 색인은 factor 를 의미
| tapply(iris$Sepal.Length,iris$Species,mean) # iris Species(범주형)3종류의 Sepal.Length의 평균을 의미 setosa versicolor virginica 5.006 5.936 6.588 tapply(1:5 , 1:5 %% 2 == 1, sum) # %% 나머지를 구하는 연산자 FALSE TRUE #1:5 %% 2 == 1는 FALSE/TRUE 구분 6 9 #FALSE(2,4) , TRUE(1,3,5) |
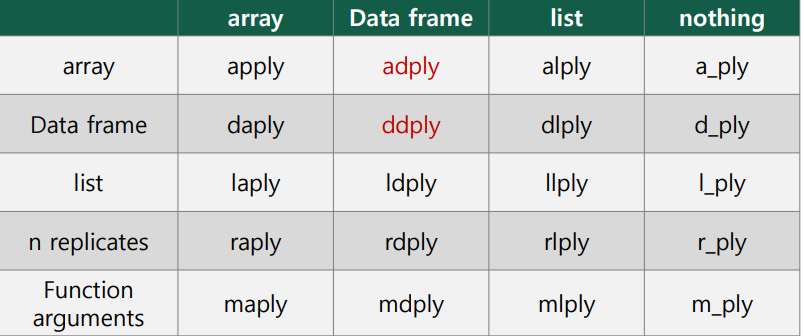
plyr 패키지 ( adply, ddply)
데이터처리함수형식
(입력데이터)(출력데이터)ply 5글자의 함수명으로 이름이 지어진다.
apply() vs adply()
| apply(iris,1,function(row){print(row)}) #apply 함수내 사용자 정의함수로 iris 출력 epal.Length Sepal.Width Petal.Length Petal.Width Species "5.1" "3.5" "1.4" "0.2" "setosa" |
apply() 함수는 벡터,행렬 , 리스트로 반환하는 함수, 결과가 한 행이면 벡터로 반환하고
여러행이면 행렬 , 각행마다 컬럼수가 다르면 리스트 결과를 반환한다.
위에 경우 벡터로 반환이 되어서 벡터의 특징( 동일한 자료형만 올 수 있다)에 의해서
모두 "setosa"의 의해 수치형 자료형이 전부 문자형으로 바뀌게 된다.
그래서,
adply()를 사용하여 결과 출력을 데이터프레임으로 해줘야한다.
| adply(iris,1,function(row){row$Sepal.Length>=5.0&row$Species=="setosa"}) Sepal.Length Sepal.Width Petal.Length Petal.Width Species V1 1 5.1 3.5 1.4 0.2 setosa TRUE 2 4.9 3.0 1.4 0.2 setosa FALSE 3 4.7 3.2 1.3 0.2 setosa FALSE # adply함수 데이터프레임으로 결과 출력하고, species=setosa 확인하고 그 결과를 v1나타냄. 즉 데이터프레임 다른 데이터 타입이 가능하여 문자형으로 표시가 안됨 |
ddply(data, variables,fun) variables = 그룹핑 변수로 .() 형식임
- 데이터프레임을 분할하고 함수에 적용후에 결과를 데이터프레임으로 반환
- adply와 ddply 차이
- adply() 는 행 또는 칼럼 단위로 함수를 적용
- ddply() 는 variables 에 나열한 컬럼에 따라 그룹으로 나눈뒤에 함수 적용
| ddply(iris,.(Species),function(sub){data.frame (Sepal.width.mean<-mean(sub$Sepal.Width))}) Species Sepal.width.mean....mean.sub.Sepal.Width. 1 setosa 3.428 2 versicolor 2.770 3 virginica 2.974 |
유용한 함수들
split()
- 데이터를 분리할 때 사용 split(데이터 , 분리조건)
- 리스트로 반환됨
| split( iris , iris $ Species) # iris 데이터를 Species 별로 분리 $'setosa' #Species가 'setosa'로 분리된 값 출력 Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa |
subset()
- 특정 값만 필터링
| # Species의 setosa 중 Sepal.Length > 5.0 인 것만 추출 > subset( iris , Species == "setosa" & Sepal.Length > 5.0) |
select()
- subset에 select 인자를 지정하면 특정 열은 선택하거나 제외용도로 사용
| #Sepal.Length와 Species열을 iris에서 선택 > subset(iris , select = c(Sepal.Length , Species )) |
attach()
- 데이터프레임에 곧바로 접근할 수 있게 한다.
- $ 없이 데이터프레임에 접근할 수 있다.
detach()
- attach() 해제하려면 detach() 사용한다.
attach() 한 변수는 detach()시 원래의 데이터 프레임에는 반영되지 않는다.(별개공간)
which()
- 벡터 또는 배열에서 주어진 조건을 만족하는 값,색인(위치)찾기
| which(iris$Sepal.Length==5.1) [1] 1 18 20 22 24 40 45 47 99 |
which.max()
| which.max(iris$Sepal.Length) [1] 132 |
which.min()
| which.min(iris$Sepal.Length) [1] 14 |
aggregate()
- 그룹별(범주형)연산을 위한 함수이다.
- aggregate(formula, 데이터, 함수)
| aggregate(sepal.length~species,iris,mean) species sepal.length 1 setosa 5.006 2 versicolor 5.936 3 virginica 6.588 |
sort()
- 오름차순으로 정렬
#sort()는 값을 정렬한 그 결과를 반환하고 원래 벡터자체를 변경하지 않는다.
'Data Science > ADsP' 카테고리의 다른 글
| [ADsP]3과목 - 2장.확률 및 확률분포 , 표본의 분포 (0) | 2020.05.25 |
|---|---|
| [ADsP]3과목 - 1장. reshape패키지,sqldf,data.table함수 , 결측값 처리와 이상값 검색 (0) | 2020.05.25 |
| [ADsP]3과목 - 1장. R 기초(R의 기초통계, 데이터 핸들링,R그래프의 이해) (0) | 2020.05.22 |
| [ADsP] 2과목 - 2장. 분석 마스터 플랜 (0) | 2020.05.20 |
| [ADsP] 2과목 - 1장. 데이터 분석 기획의 이해 ( 2 ) (0) | 2020.05.19 |