![[ADsP]3과목 - 1장. R 기초(R의 기초통계, 데이터 핸들링,R그래프의 이해)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FrZtDO%2FbtqEm2rp04u%2FAAAAAAAAAAAAAAAAAAAAADfHzXrFr2FEG44FdisVoj2j21536exovnSHIzn53VTt%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DwrDKgij%252BA7P3pkWPxlomlQyHmpk%253D)
R 기초는 밑에 링크를 통해 공부하자!!
2020/05/12 - [데이터사이언스/R] - [R] 기본 요약 정리 ( 연산 , 자료형 , vector , factor , list )
[R] 기본 요약 정리 ( 연산 , 자료형 , vector , factor , list )
RStudio 패키지 설치 및 사용 #패키지 설치 install.packages("패키지 이름") #패키지 사용 library("패키지 이름") 산술 연산 함수 함수 의미 사용 예 log() 로그함수 log(10), log(10, base = 2) sqrt() 제곱근..
acdongpgm.tistory.com
2020/05/12 - [데이터사이언스/R] - [R] 기본 요약 정리 ( data frame , 데이터 읽기/쓰기 , apply() 함수 , 데이터 찾기 )
[R] 기본 요약 정리 ( data frame , 데이터 읽기/쓰기 , apply() 함수 , 데이터 찾기 )
데이터 프레임 ( Data frame ) 데이터 프레임은 숫자형 벡터 ,문자형 벡터 등 서로 다른 형태의 데이터를 2차원 데이터 테이블 형태로 묶을 수 있는 자료구조이다. 데이터프레임 만들기 data,frame() 함�
acdongpgm.tistory.com
R의 기초통계 계산 및 인덱싱
range() : 최소값과 최대값을 반환하는 함수.
describe() 함수 : 왜도와 첨도를 알아볼 수 있음 다양한 수치들이 표시됨.
| describe(x) vars n mean sd median trimmed mad min max range skew 1 100 5.34 3.39 4.77 4.91 3.25 0.43 15.47 15.04 1.02 kurtosis se 0.73 0.34 |
Skewness(왜도) : 분포 모양 비대칭 정도 '0'정규분포 0보다 크면 왼쪽으로 치우친분포
Kurtosis(첨도) : 뾰족한 정도 3보다 크면 정규분포보다 뾰족한 모양
Mean > Median 오른쪽꼬리로 길게나와있음
Mean < Median 왼쪽꼬리로 길게나와있음
na.rm = T 옵션은 mean , range , sd 등 수치형 변수의 NA(결측값)이 있으면 결측값이 발생한다.
꼭 사용해야하는 옵션 결측값을 지운다.
인덱싱
| 데이터프레임 출력 | 벡터 값으로 출력 |
| iris[1,] iris[,c(1,2)] iris[1] iris["Sepal.Length"] |
iris[[1]] iris$Sepal.Length iris[["Sepal.Length"]] iris[,1] |
데이터 핸들링
데이터보기
str() : 데이터 구조 확인 , 변수이름, 관측치 수
새로운 변수 만들기
- 데이터명$새로운변수명<-함수 또는 수식
| df1$avg<-(height+weight)/3 |
데이터 조건으로 필터링하기 : subset()함수
예) 키가 170이상인 데이터만 추출해서 df1에 저장하기
| df1<-subset(df,subset=(height>=170)) |
데이터 열 삭제하기 : select() 함수
예)gender 변수만 삭제하고 , df2에 저장하기
| df2<-subset(df,select=-gender) |
병합하기 : merge(x,y,by)
x(병합할 데이터프레임) , y (병합할데이터프레임), by(병합할 기준 열)
ifelse(더미변수 만들 때 사용)
| gender<-ifelse(gender=="남자",0,1) gender [1] 0 0 0 1 1 |
Q10. 다음은 반복구문에 대한 설명 중 옳은 것은?
① for 구문은 괄호 안의 조건이 만족되어 있는 동안 이후의 구문을 반복한다.
② while 구문은 반복되는 구문 내에서 반복변수 i를 변화시켜 주어야 한다.
③ for 구문이 반복되는 횟수는 실행시키기 전까지 알 수 없다.
④ while 구문은 for 구문보다 빠르게 실행된다.
데이터 타입 변환
| 적용 | 결과값 |
| as.integer(3.14) | 3 |
| as.numeric(FALSE) | 0 |
| as.logical(0.45) | TRUE * 수치를 논리값으로 변경할 때는 0만아니면 다 TRUE이다 |
Q12 아래는 쥐(Rat)의 먹이 종류(Diet)에 따른 무게(Weight)의 시간(Time) 변화를 측정한 자료의 요약이다. 다음 중 이에 대한 설명으로 부적절한 것은?
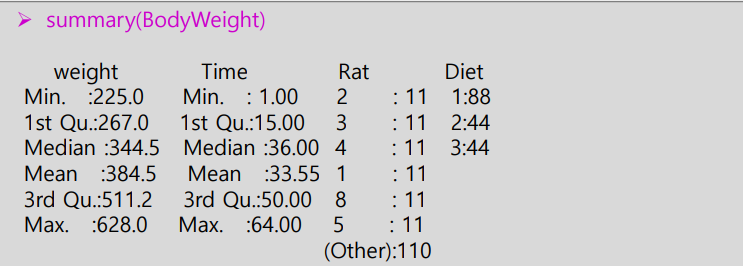
① Diet의 유형은 숫자형(Numeric)으로 인식한다.
② 데이터는 총 3가지 종류의 먹이를 포함한다
③ 명령어 ‘mean(BodyWeight$Diet)’는 오류를 발생시킨다.
④ Weight의 중위수는 344.5이다.
특수한 기능들
paste() : 입력 받은 문자열들을 하나로 붙여준다.
| number <- 1:5 alphabet <-c("a","b","c") paste(number,alphabet) [1] "1 a" "2 b" "3 c" "4 a" "5 b" paste(number,alphabet,sep=”to the”) # ‘sep=’ 옵션을 통해 붙이고자 하는 문자열들 사이에 구분자(separator) 삽입 [1] "1 to the a" "2 to the b" "3 to the c" "4 to the a" "5 to the b" |
substr() : paste 와 반대로 주어진 문자열에서 특정 문자열 추출
| country<-c("Korea","Japan") substr(country,1,2) #country 객체명에 시작위치 끝위치만 추출한 결과이다. [1] "Ko" "Ja" |
strsplit() : 문자형 벡터 변수를 split 기준으로 분리
| nation<-c("Korea,seoul","Japan,tokyo") nation_split<-strsplit(nation,split = ",") nation_split [[1]] [1] "Korea" "seoul" [[2]] [1]"japan""tokyo" |
R그래픽 이해
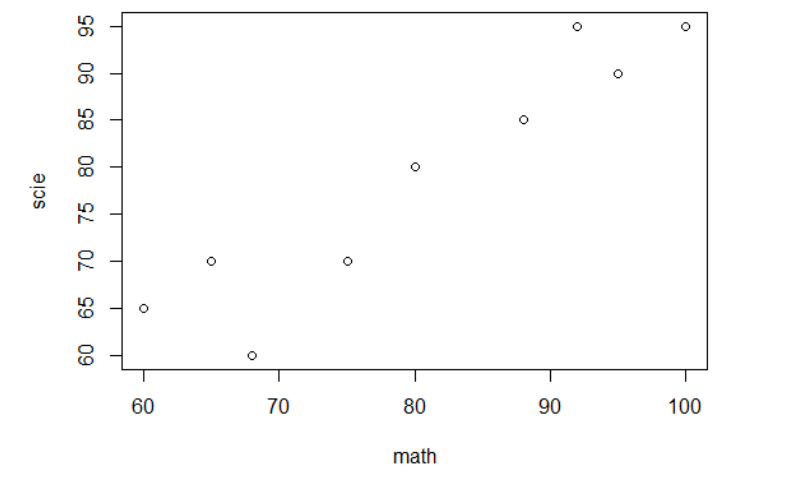
산점도(Scatter Plot) 그래프
두 양적 자료 간의 관계(선형)를 살펴보기 위해서 작성하는 그래프
plot(x,y) , plot(y~x) 같은결과
~(물결)로 할꺼면 뒤에가 x축 앞이 y축
| math<-c(95,65,80,92,60,75,88,100,75,68) scie<-c(90,70,80,95,65,70,85,95,70,60) plot(math,scie) |
산점도행렬
여러가지 변수들에 대해서 각각의 산점도를 한눈에 살펴볼 수 있도록 확장된 산점도 행렬이다.

Q13 분포 패턴이 다양한 자료에서 같은 상관계수가 도출될 수 있다. 그 패턴을 확인하기 위한 분석으로 적절한 것은?
① 상자그림 ② 산점도 ③ 빈도표 ④ 히스토그램
교차표(분할표,contingency table) : table()
두 변수를 만족하는 관측치가 각각 몇 개씩인지 파악
| gender<-c("F","M","F") bloodtype<-c("AB","O","B") height<-c(170,175,165) weight<-c(70,65,55) df<-data.frame(gender,bloodtype,height,weight) df1<-table(df$gender,df$bloodtype) AB B O F 1 1 0 M 0 0 1 |
상자 그림(boxplot)
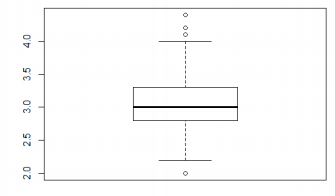 |
상자그림은 데이터의 분포를 보여주는 그림 |
| 가운데 상자 1사분위수,중앙값, 3사분위수 의미 | |
| 상자의 상하로 뻗어나간 선(whisker)은 ‘중앙값-1.5*IQR,중앙값+1.5IQR | |
| IQR은 제3사분위수-1사분위수 의미 | |
| 그림에서 보이는 점들은 이상치(outlier),lower whisker 보다 작은 데이터 1개 upper whisker 보다 큰 3개가 보인다 | |
| 위 상자그림은 iris$Sepal.Width이며, 중앙값은 약3.0,1사분위수 약2.8,3사분위수약 3.3 lowerwhisker 약 2.2,upper whisker 약 4.0 이다 |

Q14 아래 그림은 닭 사료의 종료(feed)와 닭의 성장(weight)의 관측치를 포함하고 있다. 이를 통해 추론 가능한 사실로 올바르지 않은 것은?

① casein이 포함된 사료를 먹은 닭의 몸무게 중위수가 가장 크다.
② sunflower가 포함된 사료를 먹은 닭 중 이상치의 몸무게를 가진 닭이 3마리 있다.
③ horsebean이 닭의 성장을 촉진하는데 가장 효율성이 떨어진다.
④ horsebean에 비해 meatmeal을 먹는 닭들의 몸무게의 분산이 더 작을 것이다.
히스토그램(도수분포표)
- 데이터의 분포을 알 수 있고, 히스토그램은 값의 범위마다 빈도를 표시한 그래프
- hist()로 생성
- 히스토그램의 주요 파라미터 중 하나는 frp고 , 각 구간의 확률밀도가 그려진다.
- 확률밀도로 막대 너비의 합은 1이 된다. 도수밀도(확률밀도) = 계급의도수/계급의간격
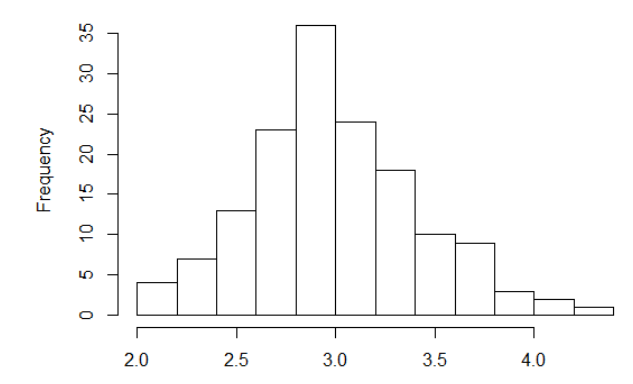
* 한화면에 여러그림 그리기
par(mfrow=c(2,2))
원래대로 돌아가기
par(mfrow=c(1,1)
Q15 히스토그램에서 각 계급에 대한 사각형의 면적을 무엇이라고 하는가?
① 도수 ② 누적도수 ③ 중앙값 ④ 계급의 크기
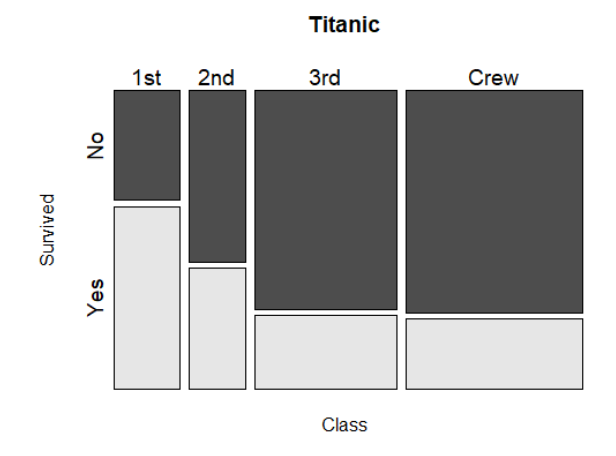
모자이크 플롯(mosaicplot)
- 모자이크 플롯은 범주형 다변량 데이터를 표현하는 데 적합한 그래프이다.
- 모자이크 플롯에는 사각형들이 그래프에서 나열되며, 각 사각형의 넓이가 범주에 속한 데이터의 수에 해당
- mosaicplot() 으로 생성
예) 타이타닉호 탑승실 등급과 생존 여부의 모자이크 플롯
mosaicplot(~Class+Survived,data=Titanic,color=True,cex=1.2)
Q16 아래의 그림은 한 대학의 합격자 현황에 대해 학과(Dept)와 합격여부(Admit) 변수를 사용해 그린 모자이크 플롯이다. 학과는 A~F 6개 학과가 있고, 합격여부는 Admitted(합격)과 Rejected(불합격)로 구분된다. 아래 그림에 대한 설명하는 보기 중 부적절한 것은?

Q17 아래는 호흡기 환자의 상태(status:poor,good)와 새로운 치료방법의 적용 여부(treatment,placebo), 각 환자의 상태를 관찰한 시점 (month:0,1,2,3,4)변수를 사용한 모자이크 플롯이다. 올바른지 않은 설명은?

① month가 1인 시점에서는 placebo와 treatment 모두 상태가 좋은(good)환자가 많다.
② month가 0~3까지는 treatment 그룹은 상태가 좋은(good)환자가 증가하는 경향이 있다.
③ treatment의 month=4인 경우 치료방법의 효과가 month=3보다 감소한다.
④ 시간의 흐름에 따라 placebo 그룹에 속한 환자 수의 비율이 treatment 그룹에 배해 증가
그래픽 기능 총정리
| 함수 | 중요 | |
| 삼전도 | plot(x,y) plot(y~x) |
2개 수치형변수의 직선=선형=상관관계를 알아보기 |
| 삼전도행렬 | pairs() | 여러개의 변수관계를 알아보기 |
| 상자그림 | boxplot() | 이상치존재IQR, 최소,최대 1사분위 3사분위 중위값 확인 NA가 기본적으로 제거하고 그려짐 |
| 히스토그램 | hist() | 연속형수치에 적합 히스토그램의 사각형 상대도수의 의미 |
| 모자이크플롯 | mosaicplot() | 사각형의 크기는 데이터의 수를 의미 |
| 막대그래프 | barplot() | 명목형 변수의 빈도에 활용(교차표)막대사이가끊겨져 있는 모양 |
'Data Science > ADsP' 카테고리의 다른 글
| [ADsP]3과목 - 1장. reshape패키지,sqldf,data.table함수 , 결측값 처리와 이상값 검색 (0) | 2020.05.25 |
|---|---|
| [ADsP]3과목 - 1장. 데이터마트와 apply함수,plyr 패키지 (0) | 2020.05.23 |
| [ADsP] 2과목 - 2장. 분석 마스터 플랜 (0) | 2020.05.20 |
| [ADsP] 2과목 - 1장. 데이터 분석 기획의 이해 ( 2 ) (0) | 2020.05.19 |
| [ADsP] 2과목 - 1장. 데이터 분석 기획의 이해 ( 1 ) (0) | 2020.05.19 |