![[기계학습] Kernel Support Vector Machines ( KSVMs , 커널 서포트 벡터 머신)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fy2PEn%2FbtqS90ngoz3%2FAAAAAAAAAAAAAAAAAAAAAPxLPFN5okNJH-NuLOIXqQYu3-USe9QHi6DG7mPDPUo-%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DR4SqEupX2hImSw7W8AgZ%252B5axbjc%253D)
SVM 은 직선을 그어 그 직선을 결정 경계로 데이터를 분류하는 알고리즘이다.
하지만 직선만 사용하면
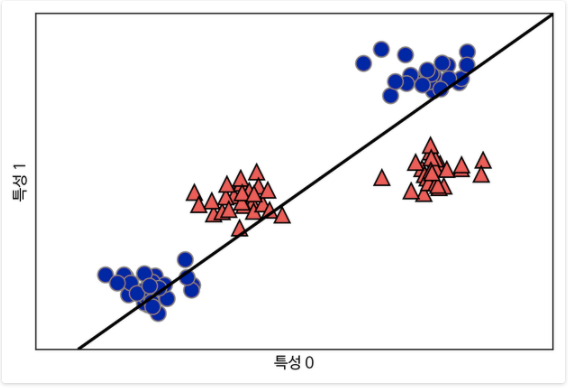
이런 데이터는 어떻게 분류할 수 있을까?
직선으로는 불가능하다.
하지만 여기서 특성을 하나 추가해주어 3차원으로 바꾸면 이 문제를 해결할 수 있다.
두 번째 특성을 제곱한 특성1 ** 2를 새로운 특성으로 추가해 입력 특성을 확장합니다
(특성 0, 특성 1, 특성 1 ** 2)의 3차원 데이터 포인트로 표현됩니다.
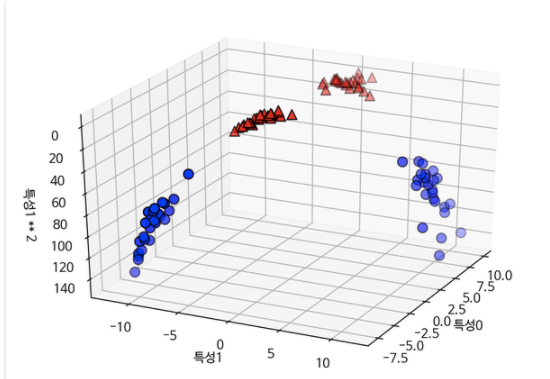
이제 3차원 공간에서 평면을 사용해 두 클래스를 구분할 수 있습니다.
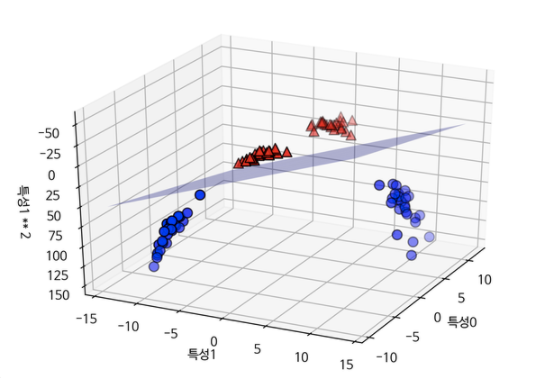
이 상태를 다시 2차원으로 투영해보면
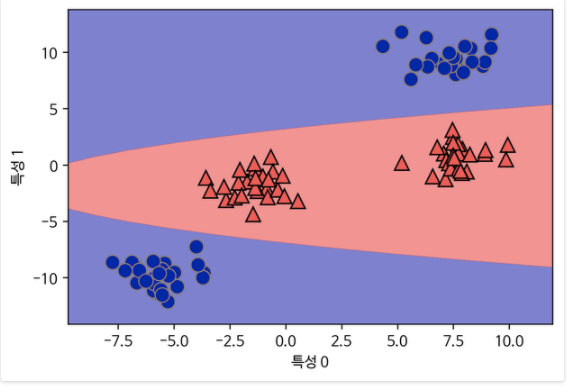
더 이상 선형이 아나라 , 직선보다 타원에 가까운 모습을 확인할 수 있습니다.
위에서 특성의 제곱을 한 값을 새로운 특성으로 사용하여 차원을 늘렸고 그것으로 문제를 해결했습니다.
하지만 많은 경우 어떤 특성을 추가해야 할지 모르고 특성을 많이 추가하면 연산비용이 커집니다.
여기서 수학적 기교를 사용해서 새로운 특성을 많이 만들지 않고서도 고차원에서 분류기를 학습시킬 수 있는 커널 기법이 있습니다.
커널기법
실제로 데이터를 확장하지 않고 확장된 특성에 대한 데이터 포인트들의 거리를 계산합니다.
SVM에서는 대표적으로 가우시안 커널로도 불리는 RBF 커널이 있습니다.
RBF 커널을 사용하면 부드럽고 비선형(직선이 아닌) 경계를 만들 수 있습니다.
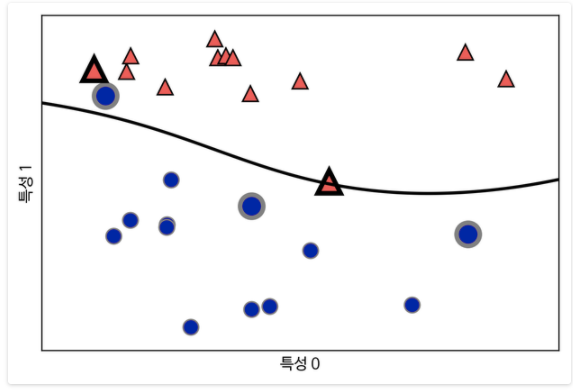
RBF 커널은 두 가지의 하이퍼 파라미터를 가지게 되는 데
C와 gamma입니다.

gamma 값이 작으면 가우시안 커널의 반경을 크게 하여 많은 포인트들이 가까이 있는 것으로 생각합니다.
작은 gamma 값이 결정 경계를 천천히 바뀌게 하므로 모델의 복잡도를 낮춥니다.
반면에 큰 gamma 값은 더 복잡한 모델을 만듭니다.
Gamma는 하나의 포인트에 대한 민감도라고 볼 수 있다.
선형 모델에서처럼 작은 C는 매우 제약이 큰 모델을 만들고 각 데이터 포인트의 영향력이 작습니다.
C를 증가시키면 이 포인트들이 모델에 큰 영향을 주며 결정 경계를 휘어서 정확하게 분류하게 합니다.
C는 하나의 포인트에 대한 영향력이라고 볼 수 있다.
2.3.7 커널 서포트 벡터 머신
2.3.6 결정 트리의 앙상블 | 목차 | 2.3.8 신경망(딥러닝) – 다음으로 다룰 지도 학습 모델은 커널 서포트 벡터 머신kernelized support vector machines입니다. 86페이지 “분류용 선형 모델”에서 선형 서포
tensorflow.blog
'Machine learning' 카테고리의 다른 글
| [기계학습] . Imbalanced Data ( 불균형 데이터 ) - SMOTE (0) | 2021.02.03 |
|---|---|
| [기계학습]. 정형데이터에서 시도해볼 수 있는 전략들 (0) | 2021.02.01 |
| [데이터 전처리]. pandas Dataframe 중복된 값 제거하기 (0) | 2020.12.04 |
| [데이터 전처리]. pandas Dataframe, Series 특수문자 제거하기 (0) | 2020.12.04 |
| [기계학습]. Cost functions (loss function) 비용 함수 (0) | 2020.11.03 |