![[기계학습] Stacking (스태킹)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fbqky7L%2FbtqVvOFfCEl%2FAAAAAAAAAAAAAAAAAAAAAOl0YFBYE94DlLFgSz1jI8QkIDh4vO5QHGmfQdJ6KZuY%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3Df%252BN7zFFxJ0%252FaPsX7nlpeK9ntW7Q%253D)
스테킹은 앙상블 기법중 하나로 정확도를 극한으로 끌어올릴 때 주로 사용된다.
우리는 분류 모델을 돌릴 때 여러가지 모델을 사용한다.
Logistic , KNN , Random Forest , Boosting 모델 등
이 모델들은 정확도가 다 다르고 보통 여기서 가장 좋은 모델을 채택하게 된다.
하지만 이 모든 모델을 합치면 어떨까?
여기서 합친다는 뜻은 모델들이 각각 유권자가 된다는 것으로 이해하면 된다.
모델들이 예측한 결과만 합쳐서 새로운 테이블을 만들어 내는 것이다.
| Logistic | KNN | Random Forest | LightGBM | XGBoost | 실제값 |
| 1 | 1 | 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 |
| 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 1 | 1 |
임의로 만들어 낸 예시 이지만
모델들의 예측결과를 이렇게 테이블 형테로 가져오고 이 상태에서 다시 예측을 진행한다.
각각의 결과값들이 Feature가 되고 이것으로 다시 학습한다.
개발자A 는 XGBoost 가 정확도가 제일 잘나와서 XGBoost를 채택했지만
XGBoost 는 80%의 정확도를 가지고 있다.
하지만 모든 모델들의 투표결과를 합친 것으로 예측하면 (스테킹을 사용하면) 정확도는 100%로 올라간다.
이 처럼 스테킹은 다른 앙상블과 같이 정확도를 높히는 방법 중 하나이다.
하지만 스테킹의 단점도 있다.
첫 번째로 오버피팅을 야기할 수 있다. 그래서 실제 기업에선 잘 사용하지 않는다고 한다.
두 번째로 시간이 너무 오래걸린다.
실제로 적용해 보았을 때 88.82% -> 90.15% 로 1.33% 증가했다.

앞서 말했듯이 극한으로 정확도를 짜낼 때 사용하는 방법이다.
스테킹을 손으로 구현하는 건 어렵지 않지만 그래도 존재하는 라이브러리를 사용했다.
knn = KNeighborsClassifier(n_neighbors=19) forest = RandomForestClassifier(n_estimators=300, random_state=0) lgb = LGBMClassifier(n_estimators=300, random_state=0) xgb = XGBClassifier(n_estimators=300, random_state=0)
from vecstack import StackingTransformer
estimators = [
('KNN' , knn ),
('RandomForest' , forest),
('lightGBM' , lgb),
('XGBoost' , xgb)
]
vecstack 라이브러리를 통해 사용할 수 있고 사용했던 모델 이름과 모델 객체를 넣어준다.
stack = StackingTransformer(estimators,
regression = False,
metric = metrics.accuracy_score,
n_folds = 4, stratified = True, shuffle = True,
random_state = 0) 여기서 스태킹의 속성을 정의한다.
모델을 돌려 정확도를 통해 K-fold 검증을하고 결과값을 저장한다.
stack = stack.fit(trainX, trainY) s_train = stack.transform(trainX) s_test = stack.transform(testX)
모델을 fitting 하고 transform 으로 훈련데이터를 기존에 사용했던 것 말고 모델들의 결과값으로 된 훈련데이터를 사용한다.
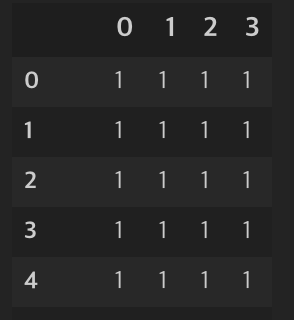
s_model = forest.fit(s_train,trainY)
s_model_prediction = s_model.predict(s_test)
accuracy = round(metrics.accuracy_score(testY, s_model_prediction) * 100, 2)
print("Accuracy : ", accuracy, "%")
모델들의 결과값으로 된 데이터프레임(s_train)과 라벨 데이터(trainY)를 가지고 다시 Random Forest로 학습한다.
예측값 비교도 스테킹한 테스트데이터(s_test)로의 예측결과를 testY 값과 비교한다.
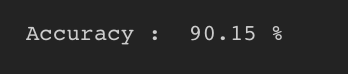
스테킹을 통해 정확도가 증가했다.
정확도가 증가했지만 오히려 AUC 가 1% 감소했다. 흠... 스테킹은 좋은 것인가?
'Machine learning' 카테고리의 다른 글
| [기계 학습] sklearn.pipeline 파이프 라인 (0) | 2021.02.10 |
|---|---|
| [데이터 전처리]. 날짜 데이터 전처리 (0) | 2021.02.09 |
| [기계학습] . Imbalanced Data ( 불균형 데이터 ) - SMOTE (0) | 2021.02.03 |
| [기계학습]. 정형데이터에서 시도해볼 수 있는 전략들 (0) | 2021.02.01 |
| [기계학습] Kernel Support Vector Machines ( KSVMs , 커널 서포트 벡터 머신) (0) | 2021.01.12 |