Machine learning
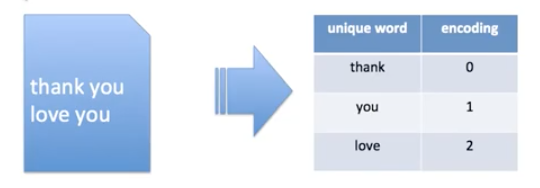
[NLP] Word Encoding & Embedding
딥러닝 모델에는 text를 input으로 넣을 수 없습니다. 그래서 text를 숫자로 변환해서 넣어주어야 하는 데 이것을 word Encoding 이라고합니다. 여기서 "Thank you love you" 를 위처럼 0 , 1 ,2 로 변환할 수 있습니다. 위 방법보다는 딥러닝에서 자주사용하는 인코딩 방법은 바로 One Hot Encdoing 입니다. 단어갯수만큼의 n차원 Vector를 만들어 독립적인 방법으로 표현하는 것 입니다. 있으면 1 없으면 0 예를들어 중복되지 않는 단어가 100개면 100차원 Vector가 됩니다. 2020/10/23 - [Data Science/Machine learning] - [데이터 전처리] . 이산형 데이터 처리하기 ( OneHotEncoding ) [데이터 전처리]..
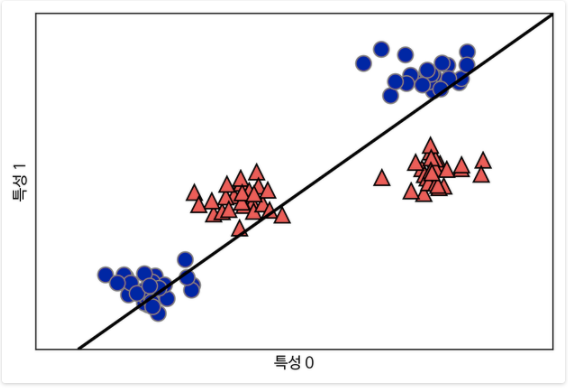
[기계학습] Kernel Support Vector Machines ( KSVMs , 커널 서포트 벡터 머신)
SVM 은 직선을 그어 그 직선을 결정 경계로 데이터를 분류하는 알고리즘이다. 하지만 직선만 사용하면 이런 데이터는 어떻게 분류할 수 있을까? 직선으로는 불가능하다. 하지만 여기서 특성을 하나 추가해주어 3차원으로 바꾸면 이 문제를 해결할 수 있다. 두 번째 특성을 제곱한 특성1 ** 2를 새로운 특성으로 추가해 입력 특성을 확장합니다 (특성 0, 특성 1, 특성 1 ** 2)의 3차원 데이터 포인트로 표현됩니다. 이제 3차원 공간에서 평면을 사용해 두 클래스를 구분할 수 있습니다. 이 상태를 다시 2차원으로 투영해보면 더 이상 선형이 아나라 , 직선보다 타원에 가까운 모습을 확인할 수 있습니다. 위에서 특성의 제곱을 한 값을 새로운 특성으로 사용하여 차원을 늘렸고 그것으로 문제를 해결했습니다. 하지만 ..

[Deep Learning] loss function - Cross Entropy
딥러닝에서 손실함수의 종류는 여러가지가 있다. 하지만 cross entropy 는 잘 이해하지 못했는데 여기서 쉽게 이해한 내용을 정리해보고자 한다. Cross-entropy 란? 틀릴 수 있는 정보(머신러닝 모델의 output) 로 부터 구한 불확실성 정보의 양이다. 잘 이해가 안되지만 밑에 예제를 살펴보자 여기서 Cross entropy 값은 딥러닝 분류문제에서 softmax 를 통해 나온 결과값과 oneHotEncoding 되어있는 정답 값의 차이라고 보면 된다. 여기서 Q를 예측한 값(Estimated PRobability) 이라고 하고 P를 정답 값(True Probability)이라고 생각해보자. cross entropy는 정보의 량(Q)에 log qi 분의 2를 사용하기 때문에 모델의 예측값..

[NLP] TF-IDF 를 활용한 제목별 추천 시스템.
컨텐츠기반 추천시스템 우리가 유튜브로 영상을 클릭하면 해당 영상과 비슷한 영상들이 오른쪽에 쭉나열된다. 이 알고리즘을 사용한 건 아니지만 TF-IDF를 통해 제목만가지고 비슷하게 한번 흉내내보자. 먼저 필요한 패키지를 불러옵니다. import pandas as pd import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity TF-IDF를 사용해야하기떄문에 sklearn 안에 있는 패키지를 불러오고 TF-IDF 값을 기준으로 코사인 유사도를 통해 가장 유사한 제목을 찾아주기떄문에 cosine_similarity를 사용합니다. 그..
[데이터 전처리]. pandas Dataframe 중복된 값 제거하기
중복된 값 확인하기. df.duplicated() # True , False 반환 df[df.duplicated] # 중복행 반환 이 함수를 사용하면 중복값이 있는지 Boolean 마스크로 확인할 수 있다. 중복된 값 제거하기 1. 중복된 행들을 제거하고 unique 한 행들만 남기기 df.drop_duplicates() 2. 중복된 것들 중 하나만 남기고 제거하기 df.drop_duplicates(['title'],keep='last') 이렇게 하면 title 행에 있는 중복값들 중에서 keep='last' 즉 , 마지막에 있는 데이터만 남기고 나머지를 다 날린다.

[데이터 전처리]. pandas Dataframe, Series 특수문자 제거하기
문자열(string) 데이터에 특수문자들이 있으면 파이썬으로 처리하기에 불편한 점이 한 두 가지가 아니다. 특히 자연어 처리에 있어서는 특수문자는 골치덩어리 (제거하기도 애매한 것들이 있음). 이번엔 다 필요없고 문자만 남기고 다 지워버리는 방법이다. 위에 데이터를 보면 ♡, [ , ] , ! , & 등 특수문자들이 보인다. 이런 것 다 없애보자. 없애는 방법은 간단하다. 정규표현식을 사용한다. df["title"] = df["title"].str.replace(pat=r'[^\w]', repl=r'', regex=True) replace( ) 함수는 조건에 맞는 것을 다른 것으로 대체 해주는 함수. r'[^\w]' 는 모든 특수문자를 뜻하는 정규 표현식. df["title"].str 을 하면 글자를 하..

[기계학습]. Cost functions (loss function) 비용 함수
[ 비용 함수(Cost Function) ] Cost Function은 입력한 Training Set에 대하여 가장 적합한 직선을 우리가 가질 수 있게 해준다. 비용함수는 원래의 값과 오차가 가장 적은 [Math Processing Error]θ를 구하여 가설함수[Math Processing Error]h를 정하는데 사용되는 함수와 같다. 에러(오차)의 값(실제값과 예측값의 차이)을 최소한으로 하는 함수를 정하는데 사용되는 함수. 말이 어렵지만.. 여기서 오차의 제곱을 해주는 데 이것은 양수와 음수의 값을 양수로 통일 시키기 위함이고 제곱을 해주었기 때문에 2차함수의 그래프가 형성된다. 이 오차(e)에 대한 2차함수 그래프를 보고 맨 밑의지점이 가장 오차가 적은 지점이고 가장 적합한 가설함수가 되는 것이..

[기계학습]. Gradient descent ( 경사하강법) 간단히 알아보기.
우리는 머신러닝을 통해 예측값을 구하는 최적의 w 값을 찾기위해 노력한다. 최적의 w란 실제값과 가장 비슷한 값을 추종하는 웨이트(w) 가중치 값이고 그 비슷한 값을 찾기 위해선 costFunction 값 ( 실제값과 차이나는 정도) 이 0이 되는 지점을 찾아야. 실제값과 가장 비슷한 w 값을 찾을 수 있다. 2020/11/03 - [Data Science/Machine learning] - [기계학습]. Cost functions (loss function) 비용 함수 [기계학습]. Cost functions (loss function) 비용 함수 [ 비용 함수(Cost Function) ] Cost Function은 입력한 Training Set에 대하여 가장 적합한 직선을 우리가 가질 수 있게 해준..

[데이터 전처리] . 데이터 구간화 ( Data binning )
데이터의 구간을 나눠보자 Equal width 값으로 구간을 나눠주는 구간화 방법 Equal frequency 빈도 수로 구간을 나눠주는 구간화 방법 샘플데이터 raw_data= {'regiment':['Nighthawks','Nighthawks','Nighthawks','Nighthawks','Dragons','Dragons','Dragons','Dragons','Scouts','Scouts','Scouts','Scouts'], 'company':['1st','1st','2nd','2nd','1st','1st','2nd','2nd','1st','1st','2nd','2nd'], 'postTestScore':[25,94,57,62,70,25,94,57,62,70,62,70]} df = pd.DataFra..

[데이터 전처리] . 이산형 데이터 처리하기 ( OneHotEncoding )
이산형 데이터를 어떻게 처리할까? { Green , Blue , Yellow } 같은 데이터들을 머신러닝 혹은 딥러닝에 활용하기 위해선 숫자의 형태로 바꿔줘야합니다. 일반적으로는 Ont-Hot-Encoding 을 많이 사용합니다. 벡터공간안에 인덱스를 부여하는 것 : 실제 데이터의 set의 크기만큼 Binary Feature를 생성한다. 데이터에 맞는 위치만 1 나머지는 다 0 데이터의 종류가 100가지라면 1개만 1이고 나머지 99개는 다 0이다. 이런식으로 표현하는 방법이 one-hot-encoding python 에서는 get_dummies( ) 함수를 활용하면 쉽게 one-hot-encoding을 할 수있다. import pandas as pd import numpy as np edges = pd..