![[데이터 전처리] . 이산형 데이터 처리하기 ( OneHotEncoding )](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F9WZS9%2FbtqLD07ZWDb%2Fuy87s0T5k8AP4rZLZcjAtK%2Fimg.png)
이산형 데이터를 어떻게 처리할까?
{ Green , Blue , Yellow } 같은 데이터들을 머신러닝 혹은 딥러닝에 활용하기 위해선
숫자의 형태로 바꿔줘야합니다.
일반적으로는 Ont-Hot-Encoding 을 많이 사용합니다.
벡터공간안에 인덱스를 부여하는 것 : 실제 데이터의 set의 크기만큼 Binary Feature를 생성한다.

데이터에 맞는 위치만 1 나머지는 다 0
데이터의 종류가 100가지라면 1개만 1이고 나머지 99개는 다 0이다. 이런식으로 표현하는 방법이 one-hot-encoding
python 에서는 get_dummies( ) 함수를 활용하면 쉽게 one-hot-encoding을 할 수있다.
import pandas as pd
import numpy as np
edges = pd.DataFrame({'source':[0,1,2],
'target':[2,2,3],
'weight':[3,4,5],
'color':['red','blue','blue']})
pd.get_dummies(edges)
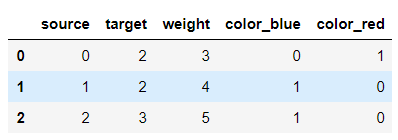
pd.get_dummies(edges["color"])
pd.get_dummies(edges[["color"]])이런 식으로도 가능합니다.
또 여기서 Weight 변수를 볼 때 이것도 순서형 등간척도 자료라고 볼 수 있습니다.
그래서 이것을 범주형 자료로 변경하고 그 자료를 다시 원 핫 인코딩 해줄 수 있습니다.
#one-hot-encoding
weight_dict = {3:"M",4:"L",5:"XL"}
edges["weight_sign"] = edges['weight'].map(weight_dict)
edges = pd.get_dummies(edges)
edges
sklearn 패키지를 활용한 one-hot-encoding 활용하기
sklearn 패키지의 원핫인코더 함수가 존재하고 간단하게 fitting 해서 사용할 수 있습니다.
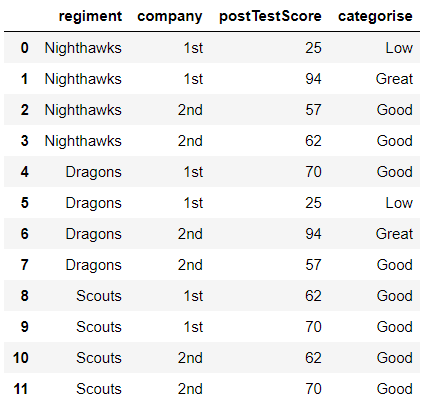
이 자료를 가지고 postTestScore를 구간화한 categorise 의 데이터를 원핫인코더로 수치화 해주겠습니다.
raw_example = df.values
data = raw_example.copy()먼저 데이터프레임의 values만 받아서 복사합니다.
from sklearn import preprocessing
#one hot encoding by sklearn
one_hot_enc = preprocessing.OneHotEncoder()
one_hot_enc.fit(data[:,0].reshape(-1,1)) # label encoding 으로 먼저 변경
onehotlabels = one_hot_enc.transform(data[:,0].reshape(-1,1)).toarray()
onehotlabelssklearn 에 preprocessing 을 임포트해서 OneHotEncoder() 객체를 생성해줍니다.
그리고 해당 자료를 fit 해주는데 여기서 data[:,0].reshape(-1,1)) 이 무엇인지 알아보겠습니다.
data[:,0].reshape(-1,1)
위 내용은 명목형 자료였던 ['categorise'] 의 값들을 reshape(-1,1) 한 결과값 입니다.
여기서 reshape(-1,1) 은 유동적으로 행은 여러개인데 열이 1개인 2차원으로 바꿔주겠다는 뜻입니다.
예를 들면 x = np.arange(12).reshape(3,4) 일 경우

이렇게 유동적으로 바뀌게 됩니다.
그 다음 fit 을 통해 규칙을 기억한 상태에서 값들을 transform 하고 그걸 리스트로 변환해주면.

ont-hot-encoding 이 잘 수행됩니다.
지금까지 이산형 , 명목형 자료를 수치형으로 바꿔주는 one-hot-encoding 에 대해서 알아봤습니다.
'Machine learning' 카테고리의 다른 글
| [기계학습]. Gradient descent ( 경사하강법) 간단히 알아보기. (0) | 2020.11.03 |
|---|---|
| [데이터 전처리] . 데이터 구간화 ( Data binning ) (0) | 2020.10.23 |
| [데이터 전처리] . 결측치 처리하기 ( Missing Values ) (0) | 2020.10.23 |
| [기계학습] KNN ( K-Nearest neighborhood ) k-최근접 이웃 (0) | 2020.07.09 |
| [기계학습] 나이브 베이즈 분류 - Naive bayes classifier (0) | 2020.07.07 |