![[데이터 전처리] . 결측치 처리하기 ( Missing Values )](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbmLDZY%2FbtqLA4DpOXl%2FsXRZWHbZfVlvwTB3VYZ2tk%2Fimg.png)
데이터가 없을 때 할 수 있는 전략
-
데이터가 없으면 없는 행을 날려버린다. ( 간단하쥬 )
-
데이터가 없는 최소 개수를 정해서 날려버린다. ( ex 결측치가 3개이상인 행은 날려버린다.)
-
데이터가 거의 없는 변수는 변수자체를 날려버린다.
-
최빈값, 평균값 , 중앙값으로 비어있는 데이터를 채운다.
-
머신러닝기법으로 예측해서 채워넣는다 ( 이 부분은 추 후에 다루도록 하겠습니다. )
샘플데이터

결측치를 확인하는 방법
df.isnull().sum()
first_name 칼럼에 1개 , last_name 칼럼에 1개 등등... 결측치가 있다.
첫 번째 방법.
결측치가 하나로 있으면 그 행을 날려버리기.
dropna() : 결측치가 있는 행은 삭제해주는 함수
df_no_missing = df.dropna()
df_no_missing* dropna() 함수는 원본데이터를 바꾸지 않고 원본데이터를 복사해서 결측치를 제거한 값을 보여주기 때문에
위처럼 새로운 변수로 반환값을 받아주거나 원본데이터의 덮어씌우기를 해줘야 합니다.

두 번째 방법.
결측치가 있는 최소개수를 정해서 행을 날려버린다.
- dropna( ) 의 인자로는 axis , how , thresh 가 있는데
- axis : 기준 축을 정해주는 것으로 axis = 1 로 설정할 경우 칼럼기준으로 결측치를 삭제한다. 열기준
- how : 어떤 결측치를 삭제할 건지를 조건을 설정해주고
how = 'all' 을 해줄경우 행의 모든내용이 비어있는 경우에만 삭제한다. - thresh : threshold 는 역치(경계) 라는 뜻이고
thresh = 3 이라고 할 경우 4개이상의 결측치가 있는 행만 제거합니다.
df_cleaned = df.dropna(how='all') #모든데이터가 nan 인 행을 지워라
df_cleaned
#데이터가 최소4개 이상 없을 때 drop
df.dropna(thresh=3) #threshold 는 역치(경계값)이라는 뜻
세 번째
데이터가 거의 없는 변수(열)을 날려 버린다.
df['location'] = np.nan모든 값이 결측치인 행을 추가한다.

#column 기준으로 삭제
df.dropna(axis=1,how='all')
location 행이 삭제됨.
네 번째
대체 값으로 채워준다.
#0으로 채우기
df.fillna(0)
결측치를 모두 0으로 채운다.
평균값 , 중위값으로 채워 넣기
#평균값, 중위값 , 최빈값(가장 많은 빈도수)
print(df["preTestScore"].mean())
print(df["postTestScore"].median())
print(df["postTestScore"].mode())
#평균값 집어 넣기
df["preTestScore"].fillna(df["preTestScore"].mean(),inplace=True)
df
fillna( ) 함수의 평균값을 넣어주면 결측치를 평균값으로 대체한다.
inplace=True 는 원본데이터를 바꾸겠다는 뜻
df = df["preTestScore"].fillna(df["preTestScore"].mean()) 과 같은 뜻이다.
GroupBy를 통하여 성별로 평균값 대체하기
#성별로 나눠서 평균값을 집어 넣기
df["postTestScore"].fillna(df.groupby("sex")["postTestScore"].transform("mean"),inplace=True)
df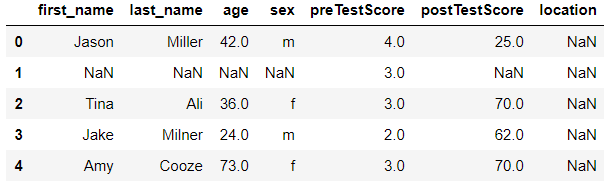
결측치가 없는 데이터만 확인하기
#age와 sex가 모두 notnull인 경우에만 표시해라
df[df['age'].notnull() & df['sex'].notnull()]
'Machine learning' 카테고리의 다른 글
| [데이터 전처리] . 데이터 구간화 ( Data binning ) (0) | 2020.10.23 |
|---|---|
| [데이터 전처리] . 이산형 데이터 처리하기 ( OneHotEncoding ) (0) | 2020.10.23 |
| [기계학습] KNN ( K-Nearest neighborhood ) k-최근접 이웃 (0) | 2020.07.09 |
| [기계학습] 나이브 베이즈 분류 - Naive bayes classifier (0) | 2020.07.07 |
| [기계학습]PCA (Principal Conponents Analysis) 주성분 분석 (0) | 2020.07.02 |