![[기계 학습]. SGD 와 mini batch ( 최적화 기법 )](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fqhm7R%2Fbtq0JwLBbSd%2FAAAAAAAAAAAAAAAAAAAAAIR5FZtHp5vpqJjc_lY_18YFC0xRUnz8JHnCsHUBj6HU%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DpyFwf%252FZrMPyTeqxDhUTGg0dn0jM%253D)
Batch size 의 개념
3명의 학생이 있고 100개의 문제를 주어졌을 때 여러가지 상황이 있다.
1번 학생 ( Batch size == 100 ) : Full-batch

1번 학생은 100개의 문제를 다 풀고 난 뒤 정답을 확인하고 수학문제 정답률을 증가시킨다.
2번 학생 ( Batch size == 10 ) : Mini-batch
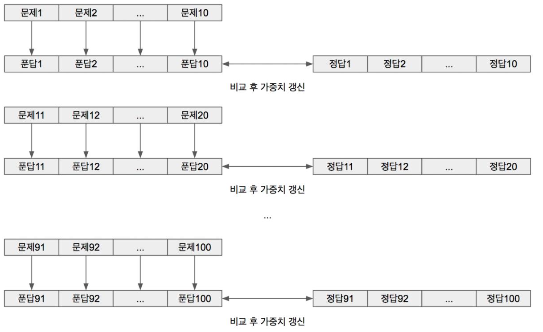
2번 학생은 100개의 문제중 10개의 문제를 보고 답안지를 보고 정답률은 향상시키고
또 다시 10개의 문제를 보고 정답률을 향상시킨다 ( 10회 반복 )
3번 학생 ( Batch size == 1 ) : SGD

3번 학생은 100개의 문제를 하나 풀고 정답보고 정답률 향상 시키고 , 하나 풀고 정답보고 ....(100회 반복)
즉 문제하나를 풀 때마다 수정 , 개선 방법을 반복한다.
위 내용과 같이 Batch Size 란 머신러닝이 데이터를 학습하는 과정에서 최적화(Gradient descent) 할 때 한번에 몇개의 데이터를 가지고 하는 지를 나타낸다.
즉 1번 학생은 100개의 데이터를 보고 최적화 하고 2번학생은 10개의 데이터를 보고 최적화 한다.
Batch Size 는 왜 생겼을까?
- 데이터가 엄청나게 많은 경우 전체데이터를 보고 최적화를 할 때 엄청난 시간이 할애할 수 있다.
- 그래서 정확도는 좀 떨어지지만 Batch Size를 줄여서 시간을 단축시키는 것이다.
SGD ( Stochastic Gradient Descent ) : 확률적 경사 하강법 ( 3번 학생의 방법 )
하나의 Training data ( Batch size = 1 ) 마다 Cost 를 계산하고 바로 Gradient descent를 적용하여 weight 를 빠르게 updatae
- 한개의 Training data 마다 매번 weight 를 갱신하기 때문에 신경망의 성능이 들쑥날쑥 변함( Cost 값이 안정적으로 줄어들지 않음 )
- 최적의 Learning rate 를 구하기 위해 일일이 튜닝하고 수렴 조건 ( early - Stop ) 을 조정해야함.

SGD 는 batch size 가 1 을 뜻하는 최적화 방법으로 위의 그림처럼 시간을 기하급수적으로 단축 시킬 수 있다.
시간만 봤을 때 효율 최고 !!
하지만 정확도 측면을 고려하면 데이터확인을 적게하기 때문에 그만큼 정밀한 정확도를 얻기 힘들다.
그럼 그 중간은 없을까?
그게 바로 mini-batch 기법이다. batch size를 1또는 max 가 아닌 적당한 값을 정해서 최적화 하는 방법이다.
Mini-Batch Stochasic Gradient Descent ( 2번 학생의 방법 )
Training data 에서 일정한 크기 ( == Batch size ) 의 데이터를 선택하여 Cost function 계산 및 Gradient descent 적용
- 앞선 두 가지 Gradient descent 기법의 단점을 보완하고 장점을 취함
- 설계자의 의도에 따라 속도와 안정성을 동시에 관리할 수 있으며, GPU 기반의 효율적인 병렬 연산이 가능해진다.

위 그래프 처럼 SGD 는 변동성이 아주크고 정확하지 않지만 속도가 빠르다, 그에 비에 Batch ( Full Batch : 기존의 사용한 GD ) 는 정확하게 수렴하지만 시간이 너무 오래걸린다.
그 중간 Mini-Batch를 통해 어느정도 시간을 절약하면서 납득할 만한 결과를 얻을 수 있다.
Batch vs Epoch , and Iteration
Batch 와 Epoch 의 차이점

총 데이터 수가 10,000개, batch size가 1,000일 경우
1 iteration = 1,000개 데이터에 대한 1회의 Gradient descent
1 epoch = 10,000 / batch size = 10 iteration ( 10회의 경사하강법 실행 )
'Machine learning' 카테고리의 다른 글
| [설치]. 리눅스 환경에서 Anaconda 설치하기 (0) | 2021.07.18 |
|---|---|
| [데이터 전처리]. tqdm pandas , apply & map progress_bar 생성 (0) | 2021.04.15 |
| [기계 학습] sklearn.pipeline 파이프 라인 (0) | 2021.02.10 |
| [데이터 전처리]. 날짜 데이터 전처리 (0) | 2021.02.09 |
| [기계학습] Stacking (스태킹) (0) | 2021.02.03 |