![[기계학습]과적합(overfitting)이란?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FZotSN%2FbtqCWMEp1H1%2FAAAAAAAAAAAAAAAAAAAAAHNE9-IiPQlHn4vslvXseegYaaRah8-GbDqPvSakcIfC%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DoR54qLEqe3RUSp9PIdJBcRFnmmw%253D)
과적합(overfitting)이란?
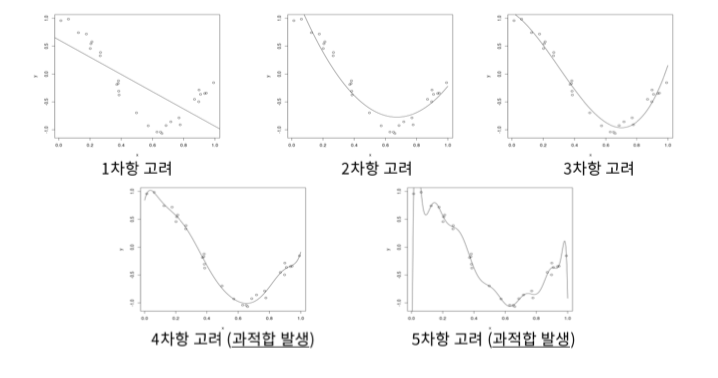
너무 과도하게 데이터 모델을 학습(learning)을 한 경우를 의미
학습 데이터에는 잘 맞지만 검증 데이터(테스트 데이터)에 잘 맞지 않는 것
- 복잡한 모형일수록, 데이터가 적을수록 과적합이 일어나가 쉽다.
- 데이터가 많으면 복잡한 모형을 써도 과적합이 잘 발생하지 않음
분산(variance)와 편파성(bias)의 트레이드오프(Tradeoff) 딜레마
분산(var) : 전체 데이터의 집합 중 다른 학습 데이터를 이용했을 때, f^ 이 변하는 정도
* 복잡한 모형일 수록 분산이 높음
편파성(bias) : 학습 알고리즘에서 잘못된 가정을 했을 때 발생하는 오차
* 간단한 모형일 수록 편파성이 높음

용어 정리 :
Tradeoff : 트레이드 오프 , 두 가지 중에 하나가 증가하면 하나는 감소하는 관계
* 딜레마의 원인
MSE(Mean Squared error) : 오류자승의 평균 기대 값 , 모형의 적합도를 판단하는 척도 수치가 낮을수록 좋은 모형
irreducible error : 변하지 않는 에러 ( 우리가 해결 할 수 없는 에러 )
reducible error : 변하는 에러 ( 우리가 수식(모형)을 바꾸면서 줄여 나갈 수 있는 에러 )
Var(f^(x)) + [bias(f^(x)]^2 + Var(e)
우리는 Var(f^(x)) + [bias(f^(x)]^2 를 바꿔나가면서 MSE를 줄여나가야 함
* overfitting도 고려해야 함
Trade-off 딜레마 설명 : 복잡하게 만들면 분산이 높아지고 간단하게 만들면 편파성이 높아짐
어쩌라는 거야.... 아오 ㄷㄷ

- 1번 모형은 사실상 불가능한 모델 ( 너무 잘 맞음 말이 안 됨)
- 2번 모형은 편파성은 낮고 분산이 높음
- 3번 모형은 편파성이 높고 분산이 낮음
- 4번 모형은 둘 다 높음 ( 쓰레기 모형 )
그럼 2번과 3번 중에 선택해야 하는데 , 즉 적절한 모형 선택과 실험 설계를 통한 과적합을 방지해야 하는데.
대부분 2번을 선택해서 과적합을 최대한 줄이는 방법을 선택한다.
*대표적으로 앙상블 모델이 2번에 해당된다.
과적합(overfitting)이 계속 나타나는 이유
우리가 가지고 있는 데이터는 모집단이 아니라 표본이기 때문에
표본이 모집단의 특성을 완벽히 대입하는 것은 어렵다( 완벽한 랜덤은 없다 )
그래서 실제 데이터와 안 맞는 현상(과적합)이 발생한다.
우리는 오버 피팅과의 싸움을 계속해야 한다.... 수많은 노력 필요!!
'Machine learning' 카테고리의 다른 글
| [Machine Learning] 단순선형회귀분석(Simple Linear Regression) 예제 ,pandas , numpy , plot (0) | 2020.05.11 |
|---|---|
| [기계학습]회귀계수의 의미 , 희귀계수 검정 ( SST , SSE , SSR , P-value ) (0) | 2020.04.28 |
| [기계학습]회귀분석 , 회귀계수 추정 , Matrix 미분 활용 (0) | 2020.04.22 |
| [기계학습]지도학습과 비지도학습 (0) | 2020.03.19 |
| [기계학습]Machine Learning의 개념 (0) | 2020.03.19 |