분류 전체보기

[데이터 과학] 데이터(Datasets) 수집하기 좋은 사이트 모음
데이터 분석에 필요한 재료 데이터들을 어디에서 수집할까요? 물론 회사에 들어가게 되면 회사 내에 데이터를 사용하기 되겠지만. 그것 외에도 많은 데이터를 수집할 수 있는 사이트가 있습니다. 1. 공공데이터 포털 https://www.data.go.kr/ 공공데이터 포털 국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase www.data.go.kr 공공데이터 포털은 가장 많이 사용하고 있는 국가기관들의 공공데이터들을 API의 형태로 다운로드할 수 있는 사이트입니다. 전국 부동산 , 범죄율 , 코로나 바이러스 등 국가기관이 수집한 데이터를 내가 수집할 수 있습니다. 2..

[기계학습] KNN ( K-Nearest neighborhood ) k-최근접 이웃
KNN (K-Nearest neighborhood) 이란? K-최근접 이웃 K는 갯수를 의미한다. ( 3NN , 5NN , 10NN ) 주변의 관측치들의 정보를 이용해서 새로운 관측치의 분류를 하게 된다. 비지도학습(Unsupervised Learning) 의 간단한 예시 아래와 같은 경우, 녹색 원(새로운 관측치)은 무엇으로 분류되어야 할까? 빨강? 파랑? 실선을 기준(K=3)으로 분류를 했을 경우는 빨강의 갯수가 더 많아서 빨강으로 분류 점선을 기준(K=5)으로 분류를 했을 경우는 파랑의 갯수가 더 많아서 파랑으로 분류 이렇게 k를 기준으로 새로운 데이터가 빨간색일지 파랑색일지 분류하는 것이 knn 알고리즘이다. 그렇다면 k는 어떻게 정하는 가? 만약 k가 너무 크다면? 미세한 경계부분은 잘못 분류할..

[기계학습] 나이브 베이즈 분류 - Naive bayes classifier
나이브 베이즈 분류에 대해서 알아보기 전에 먼저 조건부 확률에 대해서 알아보자. 조건부 확률이란? B가 주어졌을 때 사건 A의 조건부 확률 : 자료가 주어졌을 때 ( 조건을 주었을 때 ) 어떤 값의 확률을 뜻한다. 자세한 사항은 아래링크 2020/03/27 - [Data Science/Statistics] - [기초통계] 수학적 개념 ( 확률의 기초 , 확률 변수 , 확률 분포 ) [기초통계] 수학적 개념 ( 확률의 기초 , 확률 변수 , 확률 분포 ) 확률 확률 실험 ( Random experiment): 다음과 같은 속성을 지닌 관찰이나 인위적인 실험 실험결과는 미리 알 수 없다. ( ex 주사위에서 뭐가 나올지 모른다 ) 실험에서 일어날 수 있는 모든 결과는 acdongpgm.tistory.com ..
[가족] 곁을 떠난 초롱이
2020년 7월 1일 9시에 초롱이의 숨이 더 이상 뛰지않았다. 초롱이는 14년간 우리와 함께했던 반려견이다. 불과 1주일 전만해도 팔팔하게 뛰어다니던 초롱이는 심장이 부어올라 헛기침을 하기 시작하더니 하루 이틀만에 폐수종과 고혈압 판정을 받고 이틀 전 세상을 떠났다. 초롱이가 떠나는 순간 나는 26살 성인의 울음이 아닌 12살 초롱이를 처음 데려왔을 때 초등학교 5학년의 나처럼 엉엉 울었다. 초롱이가 숨을 안쉬었을 때 초롱이의 모습은 너무 편안해보였다. 폐수종으로 인해 숨을 가파르게 쉬었고 밥도 못먹고 잠도 못자고 있는 초롱이를 보면서 마음이 너무 불안했지만 야속하게도 초롱이가 세상을 떠난 후 불안한 마음보다 슬픈마음이 든 것은 심적으로 더 좋았던 것 같다. 그리고 나보다 더 슬퍼하는 엄마와 여동생을 ..

[기계학습]PCA (Principal Conponents Analysis) 주성분 분석
PCA(Principal Conponents Analysis)란 차원을 축소 즉 변수(feature)들의 갯수를 함축시키는 방법이다. 예를 들면 국어 성적과 영어성적을 합쳐서 문과적능력으로 합치는 것과 같다. 국어 , 영어 성적 ( 2차원) --> 문과적능력(1차원)으로 차원을 축소시킨다. 차원축소는 언제 사용하는가? Visualization - 시각화 3차원 이하의 데이터로 만들어 차트로 보여줘 데이터의 이해를 돕는다. reduce noise - 이미지의 노이즈 감소 preserve useful info in low memory - 메모리 절약 less time complexity - 시간절약 less space complexity - 공간절약 차원축소법(PCA) 2차원 공간상의 점을 1차원으로 줄인다..

[기계학습]회귀계수 축소법 ( Ridge regression, Ridge 회귀)
Machine Learing 기계학습 머신러닝 회귀계수 축소법을 공부하기 전에 분석용 데이터의 이상적인 조건에 대해 먼저 알아보자. 독립변수 X 사이에 상관성이 작아야 이상적임 반면에 독립변수 X와 종속변수 Y의 상관성은 커야 함. 위 두 성질을 만족하는 소수의 독립변수 집합 많은 양질의 데이터(결측치와 노이즈가 없는 깨끗한 데이터) 변수 선택(variable Selection) 독립변수 X간에는 상관성이 적고, X와 종속변수 Y간에는 상관성이 큰 독립변수만을 추출 그럼 좋은 변수는 어떤 변수일까? Y의 변동성을 잘 설명하면서 X들끼리는 상관관계가 없는 변수들이 좋은 변수이다. X1과 X2는 Y의 변동성을 설명하면서 겹치게 되고 변동성을 중복으로 가져갈 수 없기 때문에 겹치는 부분이 많아지면 하나를 제거..
[기계학습] 변수 선택법 알고리즘( Python Code - 파이썬 예제 )
#변수 선택법 def processSubset(x,y, feature_set): model = sm.OLS(y,x[list(feature_set)]) #modeling regr = model.fit() #모델학습 AIC = regr.aic #모델의 AIC return {"model" : regr , "AIC" : AIC} print(processSubset(x=trainX,y=trainY,feature_set=featureColums[0:5])) #모든 조합을 다 조합해서 좋은 모델을 반환시키는 알고리즘 import time import itertools def getBest(x,y,k): tic = time.time() #시작시간 results = [] #결과저장공간 for combo in iterto..

[기계학습]. 다중선형회귀(Multiple Linear Regression)실습 Python code -예제
실습데이터 및 파이썬 script 실습에 사용된 라이브러리 import os import pandas as pd import numpy as np import statsmodels.api as sm from sklearn.model_selection import train_test_split Pandas 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 되며 보다 안정적으로 대용량의 데이터들을 처리하는데 매우 편리한 도구 numpy 다차원 배열을 처리하는데 필요한 여러 유용한 기능을 제공 statsmodels 검정 및 추정 , 회귀분석, 시계열분석등의 다양한 통계분석 기능을 제공 patsy 패키지를 포함하고 있어 기존에 R에서만 가능했던 회귀분석과 시계열분석 방법론을 그대로 파이썬에서 이용할 수 있..

[기계학습]로지스틱 회귀분석 ( logit , odds , sigmoid 함수 )
Machine Learing 기계학습 머신러닝 로지스틱 회귀란 출력 변수를 직접 예측하는 것이 아니라, 두 개의 카테고리를 가지는 binary형태의 출력 변수(명목형) '성공','실패' 또는 '예' , '아니요' 를 예측(분류)할 때 사용하는 회귀분석 방법이다. 로지스틱 회귀에서는 k개의 입력 변수를 사용하여 성공 실패를 예측하기 위해 성공 확률 p(X)를 모델링 함. 확률에 대해서 모델링하는 방법이다. 방정식의 왼쪽의 범위는 확률이기 때문에 [0,1]이지만 오른쪽의 범위는 [-무한대 , + 무한대] 이므로 다른 형태로 모델링 해야함. 좌측항과 우측항의 범위를 맞춰주기 위해서 로지스틱 함수(Logistic Function)을 사용한다. 로지스틱 함수(Logistic Function) 1. 왼쪽항에 자연 ..
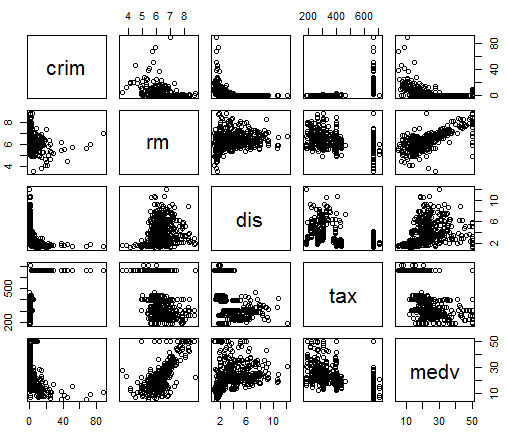
[R] 그래프 시각화 총정리 ( EDA 탐색적 분석 )
탐색적 데이터 분석 과정 실습 데이터 셋 변수 설명 변수 설명 crim 지역의 1인당 범죄율 rm 주택 1가구당 방의 개수 dis 보스턴의 5개 직업 센터까지의 거리 tax 재산세율 medv 주택 가격 1단계 : 분석 대상 데이터셋 준비 R-Code install.packages("mlbench") library(mlbench) data("BostonHousing") myds