![[기계학습]. 다중선형회귀(Multiple Linear Regression)실습 Python code -예제](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbJoHqV%2FbtqEVZnZzuZ%2FAAAAAAAAAAAAAAAAAAAAANhjgPTgRJuwqXrnWmC6aveT4Gfnjs4r9OCoGW-8UBb2%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DANHFuul%252Bw0ojsCIYa6luDatl61U%253D)
실습데이터 및 파이썬 script
실습에 사용된 라이브러리
|
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
from sklearn.model_selection import train_test_split
|
| Pandas | 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있게 되며 보다 안정적으로 대용량의 데이터들을 처리하는데 매우 편리한 도구 |
| numpy | 다차원 배열을 처리하는데 필요한 여러 유용한 기능을 제공 |
| statsmodels | 검정 및 추정 , 회귀분석, 시계열분석등의 다양한 통계분석 기능을 제공 patsy 패키지를 포함하고 있어 기존에 R에서만 가능했던 회귀분석과 시계열분석 방법론을 그대로 파이썬에서 이용할 수 있게 되었다. |
| sklearn | 머신러닝 교육을 위한 파이썬 패키지 |
| train_test_split | 딥러닝을 제외하고도 다양한 기계학습과 데이터 분석 툴을 제공하는 scikit-learn 패키지 중 model_selection에 데이터 분할을 위한 함수 |
데이터 전처리
|
#현재경로 확인
print(os.getcwd())
#데이터불러오기
corolia = pd.read_csv("./실습/part2_data/ToyotaCorolla.csv")
#데이터확인
print(corolia.head())
#데이터 수와 변수의 수 확인하기
nCar = corolia.shape[0]
nVar = corolia.shape[1]
print(nCar,nVar)
#범주형 변수를 이진형 변수( 0 ,1 )로 변환
#변수안에 범주형 변수가 있는지 확인
print(corolia.Fuel_Type.unique())
#가변수 생성
dummy_p = np.repeat(0,nCar)
dummy_d = np.repeat(0,nCar)
dummy_c = np.repeat(0,nCar)
#인덱스 슬라이싱 후 1 대입
p_idx = np.array(corolia.Fuel_Type=="Petrol")
d_idx = np.array(corolia.Fuel_Type=="Diesel")
c_idx = np.array(corolia.Fuel_Type=="CNG")
print(p_idx,d_idx,c_idx)
dummy_p[p_idx] = 1
dummy_d[d_idx] = 1
dummy_c[c_idx] = 1
#불필요한 변수 제거 및 가변수 추가
Fuel = pd.DataFrame({"Petrol":dummy_p, "Diesel": dummy_d, "CNG":dummy_c})
corolia_ = corolia.drop(["Id","Model","Fuel_Type"],axis=1,inplace=False)
mlrData = pd.concat((corolia_,Fuel),1)
mlrData.head()
cs |
| shape | array 에 대해서 몇행, 몇열 행렬로 구성되었는지 알아야 할 경우 사용되는 numpy 함수 |
| unique( ) | 배열 내 중복된 원소 제거 후 유일한 원소를 정렬하여 반환 |
| np.repeat( ) | numpy.repeat 함수는 배열의 요소들을 지정한 횟수만큼 반복합니다. |
| np.array( ) | NumPy의 array라는 함수에 리스트를 넣으면 배열로 변환해 준다. |
| pd.DataFrame( ) | pandas dataframe은 다양한 데이터 타입으로부터 만들 수 있다. pd.DataFrame({"Petrol":dummy_p, "Diesel": dummy_d, "CNG":dummy_c}) Petrol , Diesel , CNG 는 column 이고 dummy는 순서데로 row가 된다. |
| drop( ) | drop 함수를 이용하면 선택한 값이 삭제된 새로운 객체를 얻을 수 있음. "inplace=" 는 True 일 경우 결과를 다시 대입(=)하지 않아도 됨. "axis=1"는 y축 방향 즉 column 에 대한 내용을 뜻함. |
| pd.concat( ) |
데이터의 속성 형태가 동일한 데이터셋끼리 합칠 때 사용할 수 있는 pandas의 DataFrame 합치는 방법 |

Discription :
실습데이터의 Fuel_Type이라는 변수가 범주형 변수로 되어있어 회귀분석을 진행할 경우 문자열 데이터가 들어있기 때문에 데이터분석이 어렵다. 그래서 이 범주형 변수를 참/거짓 즉 0과1로 구별하여 column에 추가하고 불필요한 변수들을 제거하여 데이터분석이 용이한 상태로 만들어줘야한다.
상수항 추가 및 데이터 분할
|
#bias 추가
#상수항 추가 ( 상수항 추가는 한번 더 실행시키면 추가가 더 된다 주의!!)
mlrData = sm.add_constant(mlrData,has_constant="add")
print(mlrData.head())
#설명변수(X) ,타겟변수(Y) 분리 및 학습데이터와 평가데이터 분할
featureColums = list(mlrData.columns.difference(["Price"]))
x = mlrData[featureColums]
y = mlrData.Price
trainX ,testX , trainY , testY = train_test_split(x,y,train_size=0.7,test_size=0.3)
print(trainX.shape,testX.shape,trainY.shape,testY.shape) |
| sm.add_constant | 회귀분석모형 수식을 간단하게 만들기 위해 다음과 같이 상수항을 독립변수 데이터에 추가하는 것을 상수항 결합(bias augmentation)작업이라고 한다. 상수항 결합을 하게 되면 모든 원소가 1인 벡터가 입력 데이터 행렬에 추가된다. 데이터프레임을 만들 때 데이터 행이 하나인 경우에는 add_constant에 has_constant="add" 인수를 추가해야 한다. |
| difference | 반환 된 세트에는 두 세트가 아닌 첫 번째 세트에만 존재하는 항목이 포함됩니다. mlrData.columns.difference(["Price"]) mlrData의 칼럼들중에 Price 빼고 전부다를 반환한다. |
| train_test_split | 형식 : train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)
test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25) |
회귀모델 적합 및 다중공선성 확인
|
#Train the MLR / 회귀모델적합
fullModel = sm.OLS(trainY,trainX)
fittedFullModel = fullModel.fit()
#R-Squre 가 높고 , 대부분의 변수들이 유의함.
print(fittedFullModel.summary())
#VIF를 통한 다중공선성 확인
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(mlrData.values,i)
for i in range(mlrData.shape[1])]
vif["features"]=mlrData.columns
print(vif)
|
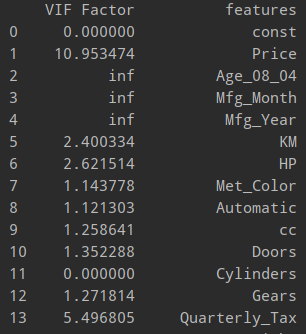 다중공선성 확인 |
 summary( ) 함수를 통한 p-value 확인 |
Age_08_04 , Mfg_Month , Mfg_Year 의 다중공선성 값이 inf로 무한대이기 때문에 변수를 제거하는 게 맞지만
p-value를 보면 유의미한 변수라는 것을 알 수 있기 때문에 변수를 제거하지않고
변수선택법을 통한 무의미한 변수를 줄이는 작업을 거쳐야한다.
| sm.OLS( ) | OLS(Ordinary Least Squares)는 가장 기본적인 결정론적 선형 회귀 방법으로 잔차제곱합(RSS: Residual Sum of Squares)를 최소화하는 가중치 벡터를 행렬 미분으로 구하는 방법이다. |
| fit( ) | fit( ) 함수를 통해 모델을 훈련하고 predict( )함수를 사용해 예측을 만들 수 있다. |
| predict( ) | 모델을 만들고 나면 새로운 데이터에 대한 예측값은 predict( )로 구할 수 있다. |
학습데이터 검증
|
#학습데이터의 잔차 확인
res = fittedFullModel.resid
import matplotlib.pyplot as plt
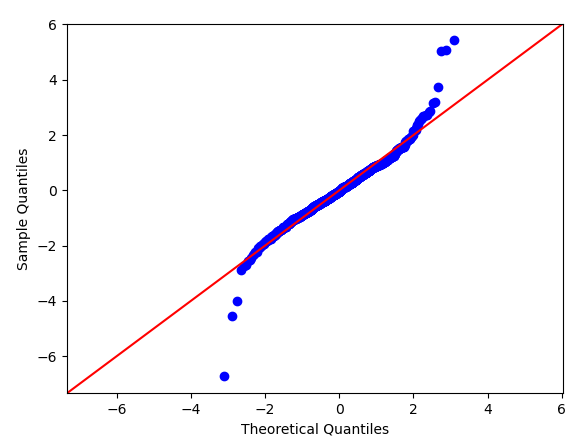
#Q-Q plot # 정규분포확인
fig = sm.qqplot(res, fit=True, line='45')
plt.show()
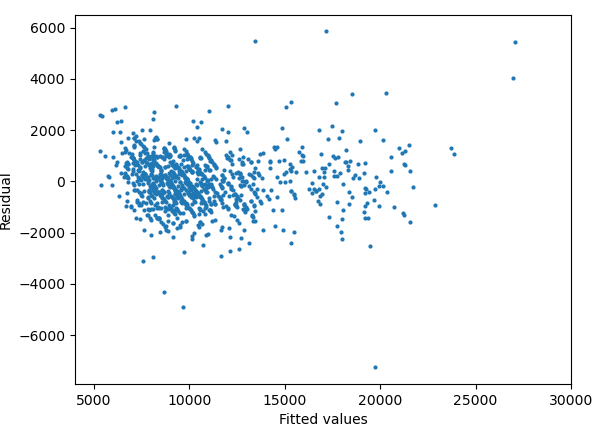
# residual pattern 확인
predY = fittedFullModel.predict(trainX)
fig = plt.scatter(predY,res,s=4)
plt.xlim(4000,30000)
plt.xlim(4000,30000)
plt.xlabel('Fitted values')
plt.ylabel('Residual')
plt.show()
#검증 데이터에 대한 예측
predY2 = fittedFullModel.predict(testX)
plt.plot(np.array(testY-predY2),label="predFull")
plt.legend()
plt.show()
#MSE 값 구하기
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(y_true=testY,y_pred=predY2)
print(MSE)cs
|
라이브러리
| matplotlib | 파이썬에서 자료를 차트(chart)나 플롯(plot)으로 시각화(visulaization)하는 패키지이다. |
라이브러리 함수 설명
| resid | 잔차확인 |
| sm.qqplot( ) | sm.qqplot(res, fit=True, line='45') sm.qqplot( 잔차 , 직선 ) |
| plt.show( ) | 그래프를 윈도우 창으로 띄워준다. |
| plt.scatter( ) | 데이터의 특징에 따라 애초에 점으로 된 그래프를 적용해 그에 특징적인 스타일을 적용하는 게 더 효과적일때가 있습니다. |
| plt.xlim( ) | 축 범위 바꾸기 plt.xlim([보여줄 최소값, 보여줄 최대값]) 를 사용하면 된다. |
| plt.plot( ) | 데이터집합에 대한 그래프를 그려주는 함수 |
| plt.legend( ) |
그래프 안에 위의 설명을 표시해주는 함수 |

출력된 시각화 데이터
Q-Q plot
Residual vs Fitted values
검증 데이터에 대한 예측

MSE 값 구하기

'Machine learning' 카테고리의 다른 글
| [기계학습]회귀계수 축소법 ( Ridge regression, Ridge 회귀) (0) | 2020.06.25 |
|---|---|
| [기계학습] 변수 선택법 알고리즘( Python Code - 파이썬 예제 ) (0) | 2020.06.18 |
| [기계학습]로지스틱 회귀분석 ( logit , odds , sigmoid 함수 ) (0) | 2020.06.16 |
| [기계학습]다항 회귀 분석 ( 비선형 회귀 분석 ) (0) | 2020.06.16 |
| [기계학습]회귀분석의 진단 ( nomal Q-Q plot ,Residual vs Fitted, Residuals 산점도 ) (0) | 2020.06.16 |