Machine learning/NLP

[NLP] Sequence to Sequence(시퀀스 투 시퀀스) 코드
https://acdongpgm.tistory.com/216 [NLP] Sequence to Sequence (시퀀스 투 시퀀스), Attention(어텐션) 개념 시퀀스 투 시퀀스 모델은 셀프 어텐션의 등장으로 요즘에 잘 사용하지 않지만 자연어 처리에서 중요한 개념을 내포하고 있고 Many to Many task에 대해서 자세히 알아볼 수 있다. 그리고 꼭 얻어가야 acdongpgm.tistory.com 시퀀스 투 시퀀스의 모델 구조와 어떻게 동작하는지에 대해 코드를 통해 이해해 보고자 한다. 예제에서 사용한 데이터 셋은 연애 질문에 대한 Q&A 데이터이고 시퀀스 투 시퀀스로 간단한 챗봇을 만들고자 한다. 출처 : 텐서 플로 2와 머신러닝으로 시작하는 자연어 처리 위 책에 있는 예제를 그대로 따라 해보..

[NLP] Sequence to Sequence (시퀀스 투 시퀀스), Attention(어텐션) 개념
시퀀스 투 시퀀스 모델은 셀프 어텐션의 등장으로 요즘에 잘 사용하지 않지만 자연어 처리에서 중요한 개념을 내포하고 있고 Many to Many task에 대해서 자세히 알아볼 수 있다. 그리고 꼭 얻어가야 할 것은 시퀀스 투 시퀀스는 어떤 게 문제였고 현재는 그 문제를 어떻게 개선했는지에 대해서 반드시 알 필요가 있다. 먼저 시퀀스(Sequence)란 무엇일까? 시퀀스란 말은 영화에서 몇 개의 관련된 장면을 모아서 이루는 구성단위로도 쓰이고 전기 회로를 구성한 도면을 말하기도 한다. 이 처럼 여러 분야에서 각기 다르게 쓰이는데 자연어 처리에서는 단어들이 2개 이상 묶여있는 것으로 이해하면 된다. [ i , am , a ,boy ] 시퀀스 투 시퀀스 모델(Sequence to Sequence model) ..
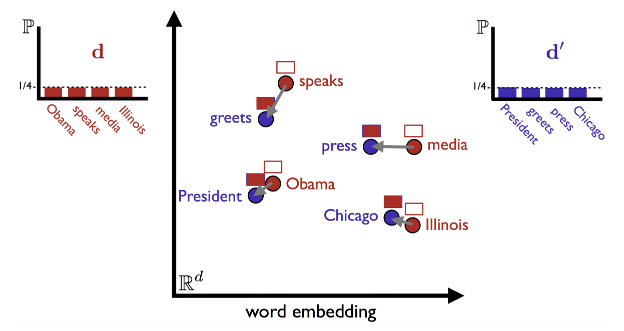
[NLP] 수능 영어지문을 풀어주는 인공지능 (WMD)
이번에 진행한 프로젝트는 수능 영어 지문 중에서 주제를 찾는 문제를 풀어보는 인공지능을 구현해 보겠습니다. from nltk import download from nltk import word_tokenize from nltk.corpus import stopwords from nltk.stem.lancaster import LancasterStemmer from nltk.stem import WordNetLemmatizer import nltk download('stopwords') stop_words = stopwords.words('english') import pandas as pd import numpy as np 먼저 기본적인 영어 NLP 를 처리해주는 패키지를 사용했습니다. def _prep..
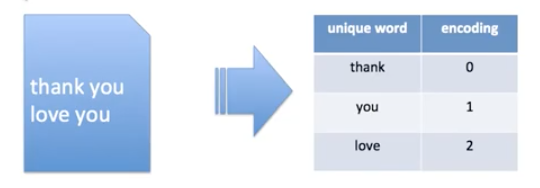
[NLP] Word Encoding & Embedding
딥러닝 모델에는 text를 input으로 넣을 수 없습니다. 그래서 text를 숫자로 변환해서 넣어주어야 하는 데 이것을 word Encoding 이라고합니다. 여기서 "Thank you love you" 를 위처럼 0 , 1 ,2 로 변환할 수 있습니다. 위 방법보다는 딥러닝에서 자주사용하는 인코딩 방법은 바로 One Hot Encdoing 입니다. 단어갯수만큼의 n차원 Vector를 만들어 독립적인 방법으로 표현하는 것 입니다. 있으면 1 없으면 0 예를들어 중복되지 않는 단어가 100개면 100차원 Vector가 됩니다. 2020/10/23 - [Data Science/Machine learning] - [데이터 전처리] . 이산형 데이터 처리하기 ( OneHotEncoding ) [데이터 전처리]..

[NLP] TF-IDF 를 활용한 제목별 추천 시스템.
컨텐츠기반 추천시스템 우리가 유튜브로 영상을 클릭하면 해당 영상과 비슷한 영상들이 오른쪽에 쭉나열된다. 이 알고리즘을 사용한 건 아니지만 TF-IDF를 통해 제목만가지고 비슷하게 한번 흉내내보자. 먼저 필요한 패키지를 불러옵니다. import pandas as pd import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity TF-IDF를 사용해야하기떄문에 sklearn 안에 있는 패키지를 불러오고 TF-IDF 값을 기준으로 코사인 유사도를 통해 가장 유사한 제목을 찾아주기떄문에 cosine_similarity를 사용합니다. 그..