사람들이 채팅에서 사용하는 채팅체(구어체) 데이터들은 오타 혹은 줄임말등을 많이 사용하게 된다.
그러나 한글의 위대함 때문인지 오탈자를 사용하더라도 문맥에는 크게 지장가지 않는다.
그래서 친분이 있는 경우라면 더욱더 채팅할때 오타를 신경쓰지 않게된다.(나도 마찬가지)
기본적인 띄어쓰기 오류 , 애교가 섞인 말투(의도적) , 신조어 , 줄임말 등등,,,
하지만 인공지능 챗봇을 학습시킬때는 오타가 많을 경우 학습하기 어려운 측면이 있다.
물론 요즘 서브워드 기반인 워드피스 토크나이저를 사용하면 오타를 어느정도 보완하는 측면이 있지만.
오타를 정규화 해주는 게 좋은 성능을 야기할 수 있다.
이번 포스팅에서는 구어체 말뭉치를 가지고 자주 사용되는 오타를 확인해보고자한다.
말뭉치 데이터
AI-hub SNS 데이터 셋 : https://aihub.or.kr/aidata/30718
말뭉치 전처리
(1). 사용자 발화 데이터 정제 ( json to txt )
(2). 마스킹된 데이터 제외 ( #@이름# , #@장소# , #@이모티콘# )
(3). 반복 규제 ( ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ -> ㅋㅋ )
사용자 발화를 한줄씩 구분 전처리

말뭉치 데이터 준비완료 ( 3,400,000 건 )
편집거리 알고리즘 사용
참고 :
편집거리 알고리즘 : https://lovit.github.io/nlp/2018/08/28/levenshtein_hangle/
편집거리 알고리즘 속도 향상 : https://lovit.github.io/nlp/2018/09/04/levenshtein_inverted_index/
편집 거리 알고리즘 오픈소스(Git) : https://github.com/lovit/levenshtein_finder
패키지 다운로드
!pip install levenshtein_finder
편집거리 알고리즘 패키지 사용
from levenshtein_finder import LevenshteinFinder , CharacterTokenizer , Normalizers
from tqdm import tqdm
import itertools
corpus_fname = './utterance_corpus.txt' # 생성한 말뭉치 경로
# 말뭉치 단어 토크나이징(split)
corpus = [sent.strip().split(" ") for sent in tqdm(open(corpus_fname, 'r', encoding='utf-8').readlines())]
# 2차원 리스트(문장이 단어로 분리된)를 1차원으로 통합(단어 단위)
corpus = list(itertools.chain(*corpus))
# 중복된 단어 제거
corpus = list(set(corpus))
# 자소 단위로 쪼개서 편집거리를 구하는 알고리즘.
normalizer = Normalizers.create_normalizer(unicodedata=True)
tokenizer = CharacterTokenizer(normalizer=normalizer)
finder = LevenshteinFinder(tokenizer=tokenizer)
finder.indexing(corpus)
사용 예시
finder.search("뭐해?", verbose=True)
실행 결과
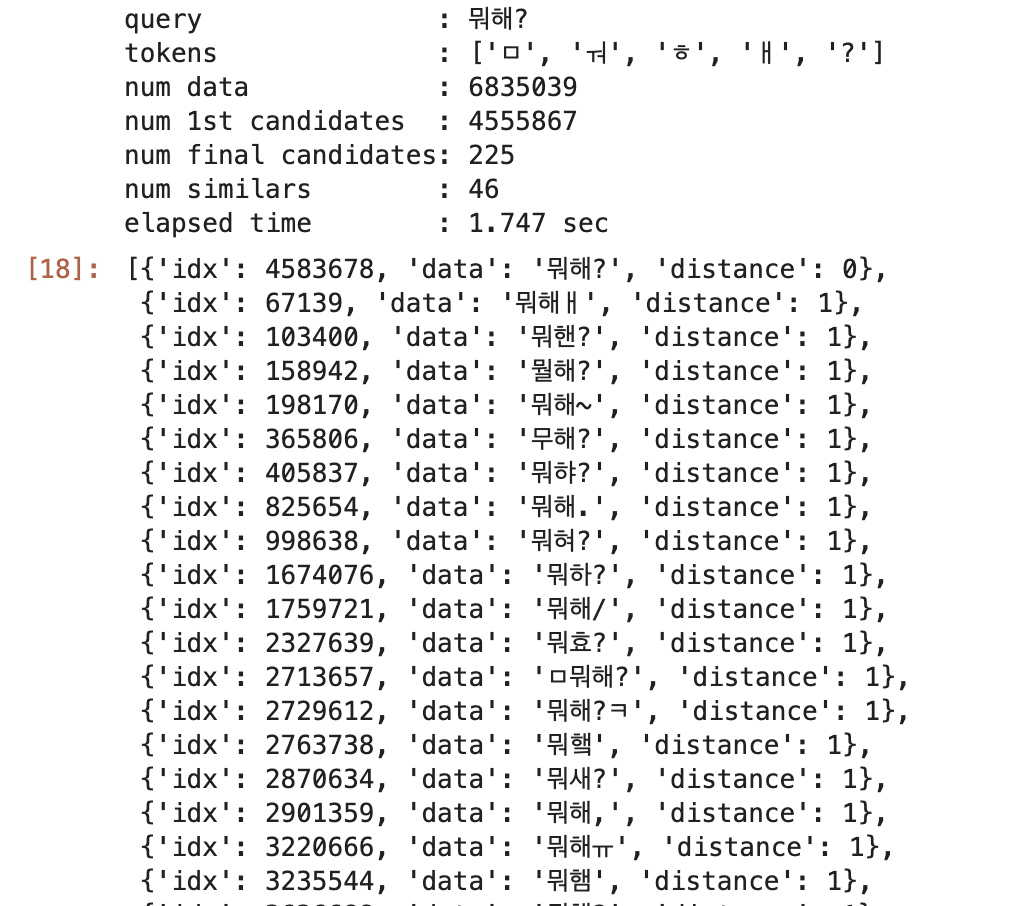
편집거리를 통해 비슷한 단어를 도출하고 사용자가 보고 판단하여 오타 여부를 확인함.
오타 교정 사전을 구축하여 사용하면
규칙 기반 오타 교정기를 구현할 수 있을 것이다.
'Machine learning > Chatbot' 카테고리의 다른 글
| [chatbot]. 핑퐁 빌더 API 연동하기 (1) | 2022.12.05 |
|---|---|
| [챗봇] faiss로 빠르게 유사도 검색하기(Similarity Search) (0) | 2022.07.18 |
| [챗봇]. BERT 임베딩 벡터를(Embedding Vectors) RDBMS의 저장해야하는 이유 (1) | 2022.02.13 |
| [챗봇]. 대화 텍스트 길이(length)에 대한 패널티(penalty)를 주는 방법 (0) | 2021.11.14 |
| [챗봇] 아주 간단한 검색기반 챗봇 만들기(feat.pororo) (1) | 2021.08.31 |