![[NLP] . OOV 를 해결하는 방법 - 1. BPE(Byte Pair Encoding)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbdGW00%2FbtrcNMwdP5B%2Fhj5llOZAk05GaANZK6Fhgk%2Fimg.png)
컴퓨터가 자연어를 이해하는 기술은 크게 발전했다.
그 이유는 자연어의 근본적인 문제였던 OOV문제를 해결했다는 점에서
큰 역할을 했다고 본다.
사실 해결이라고 보긴 어렵고 완화가 더 맞는 표현인 거 같다.
사람들도 모르는 단어 있으면 이해하기 어려운건 마찬가지
OOV(Out-Of-Vocabulary) 문제란 무엇일까?
말 그대로 단어 사전에 없다는 뜻이다.
자연어의 전처리 과정에서는
학습데이터의 모든 단어를 토큰화 하여 Vocabulary를 만들고
그 Vocabulary 를 기준으로 정수 인코딩(단어를 숫자로 표현함)을 하게된다.
실제 사용할 때(검증 혹은 상용화)도 이 과정을 반복하는데
새로운 단어 토큰이 들어왔을 때 vocabulary에 없을 경우 <UNK> unknown token을 반환한다.
* 실제 경험담을 이야기해보면 가사 감정 분류 프로젝트를 했을 때
지코 - Tough cookie의 분석 결과가 이상하게 나온 적이 있다.
(*가사 내용은 분노를 표출하는 가사)
가사에서 반복되는 분노 표출 단어는
"잘못 씹다가 이빨 다나 갈 수 있어",
"넌 친구도 아니야"
"디스" 등이 있었지만
여기서 등장한 단어들( 이빨 , 씹다, 디스 )등이 OOV 문제를 겪게 되면서 모델이 이해할 수 없었고
"내 노래", "내 앨범" , "싱어송라이터" 들이 단어들이 모델의 중요하게 작용해서
"분노"감정이 아닌 "신나는"감정으로 오분류해버렸다.
이 처럼 OOV 문제는 자연어에서 치명적인 문제로 다가왔다.
이 알고리즘을 접하기 전까지 말이다. ( 이걸 미리 알았더라면 내 프로젝트도.... ㅠㅠ )
전 프로젝트에서 나는 형태소 분석기로 토크 나이징 했지만..
서브 워드 분리(Subword segmenation) 방법을 소개하겠습니다.
작업은 하나의 단어는 더 작은 단위의 의미 있는 여러 서브 워드들의 조합으로 구성된 경우가 많기 때문에
하나의 단어를 여러 서브 워드로 분리해서 단어를 인코딩 및 임베딩 하겠다는 의도를 가진 전처리 작업입니다.
Birthplace = Birth + Place ( 서브 워드로 분리 )
다행히 영어와 한국어는 서브워드 분리를 시도했을 때 어느 정도 의미 있는 단위로 나누는 것이 가능합니다.
BPE(Byte Pair Encoding)
논문 : https://arxiv.org/pdf/1508.07909.pdf
방법을 간단히 설명하면
단어들을 최소 단위(characters)로 쪼개서 빈도 수기반으로 병합하는 기법입니다.
dict = { low : 5, lower : 2, newest : 6, widest : 3 }
기존 방식의 문제점 : 'lowest' 단어가 등장하면 OOV 문제 발생
BPE 알고리즘을 사용한 경우
# dictionary l o w : 5, l o w e r : 2, n e w e s t : 6, w i d e s t : 3잘게 쪼겐 상태에서 Vocabulary를 만든다.
# vocabulary l, o, w, e, r, n, w, s, t, i, d
BPE의 특징은 알고리즘의 동작을 몇 회 반복(iteration)할 것인지를 사용자가 정합니다. *하이퍼 파라미터
총 10회 수행한다고 예를 들어보면
1회 - 딕셔너리를 참고로 하였을 때 빈도수가 9로 가장 높은 (e, s)의 쌍을 es로 통합합니다.
# dictionary update! l o w : 5, l o w e r : 2, n e w es t : 6, w i d es t : 3# vocabulary update! l, o, w, e, r, n, w, s, t, i, d, es
2회 - 빈도수가 9로 가장 높은 (es, t)의 쌍을 est로 통합합니다.
# dictionary update! l o w : 5, l o w e r : 2, n e w est : 6, w i d est : 3# vocabulary update! l, o, w, e, r, n, w, s, t, i, d, es, est
3회 - 빈도수가 7로 가장 높은 (l, o)의 쌍을 lo로 통합합니다.
# dictionary update! lo w : 5, lo w e r : 2, n e w est : 6, w i d est : 3# vocabulary update! l, o, w, e, r, n, w, s, t, i, d, es, est, lo
10회 - 같은 반복으로 병합하면서 Vocabylary를 업데이트함.
# dictionary update! low : 5, low e r : 2, newest : 6, widest : 3# vocabulary update! l, o, w, e, r, n, w, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest
이제 'lowest' 단어가 들어올 경우 OOV를 발생시키지 않고
'low' , 'est' 두 단어로 인코딩할 수 있게 됨.
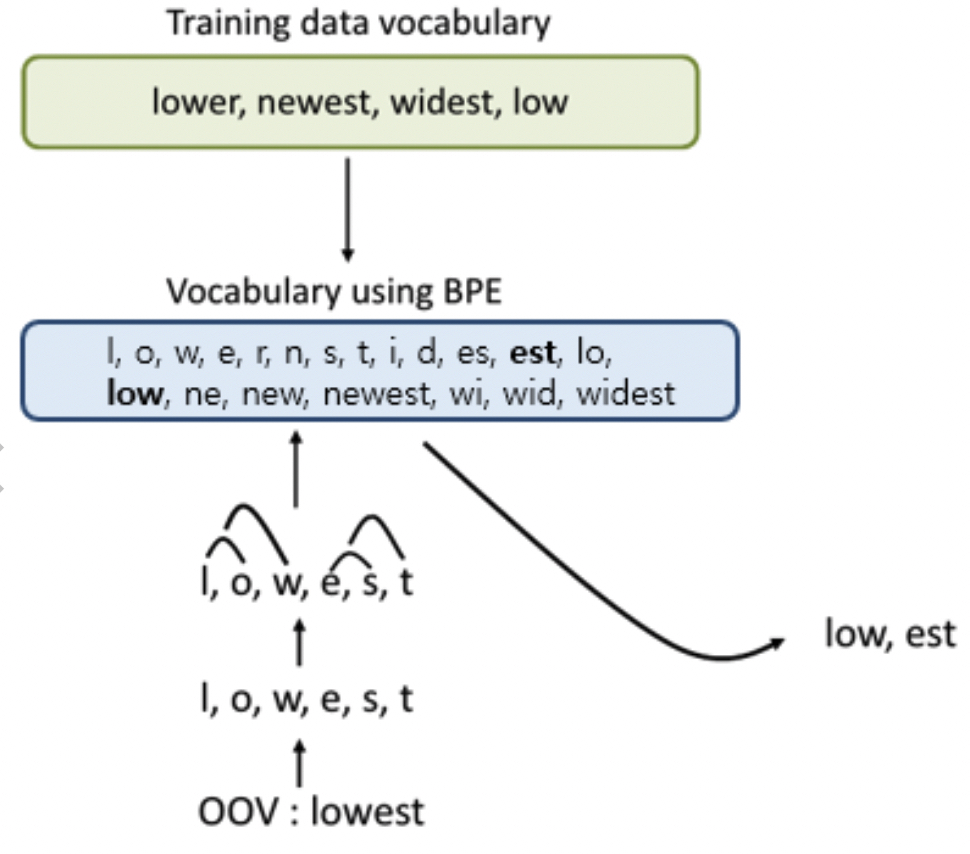
이렇게 처리하면 OOV 문제 해결뿐만 아니라 희귀 단어, 신조어 같은 문제를 완화시킬 수 있음.
참고 : https://wikidocs.net/22592
'Machine learning > NLP' 카테고리의 다른 글
| [NLP] . 자연어처리 프로젝트 파일 구조 ( 인공지능 디자인 패턴 ) (0) | 2021.09.05 |
|---|---|
| [NLP] BERT - (1).구조와 개념 (0) | 2021.09.04 |
| [NLP] Transformer : Masked Multi-Head Attention - part3 (0) | 2021.08.21 |
| [NLP] Transformer : Self-Attention ( Multi-head-Attention ) - part2 (0) | 2021.08.19 |
| [NLP]. Transformer : Structure - part1 (0) | 2021.08.19 |