![[Project] 판교에 취업한다면 어느 동네에 집을 구할까](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbK49gE%2FbtqIhZZxWtS%2FngVCjvwlDVTWyGhSRt5eQk%2Fimg.png)
github.com/alswhddh/myproject/tree/master/Crawling
Project 1.
판교에서 취업한다면 어느 동네에 집을 구할까?
Goal
거리 , 주택 매매가, 편의시설 등의 조건별 우선순위를 부여하여 거주에 적합한 동네를
추천하는 Product
Outline
경기도 성남시의 행정구역 26개 구역을 대상으로 조건 데이터를 조사 분석하고,
사용자 맞춤 가장 살기 좋은 동네 순위를 알아본다.
Process
Step 1. 데이터 수집
- 판교역 중심지와 동 주민센터간의 거리, 주택 실거래가, 동별 범죄 검거율 , 편의시설 수
- 판교역 간 거리 측정 -> 네이버 길찾기 자동입력 및 크롤링으로 수집
- 각 동별 동사무소와 판교역 간 네이버 길찾기로 자동입력 후 웹 크롤링한다.
- 대중교통시간(분) / 자동차시간(분) / 자동차거리 동 별 정리한다.
성남시 구별 검거율 - > 성남시 파출소 자료 수집
구별로 묶어 자료형을 정리하고 범죄 데이터 검거율 계산한 후 , 각 동을 구별로 평균검거율로 정리한다.
편의 시설 자료 - 마트, 공원 , 의원 , 카페 , 편의점 수 ( * 기준연월 2020년 6월 )
전체 csv 파일 중 성남시를 대상으로, 영업상태 필드 중 영업중인 데이터만 추출한다.
주택가격 - 아파트 매매 실거래 자료 현황, 단독_다가구매매실거래 자료현황
아파트 평당 가격과 단독_다가구_평당 가격 계산한다.
행정구역 조사하여 동별로 편의시설 분포 수 정리한다. ( 데이터가 없는 구역은 제외한다. )
Step 2.데이터 전처리
전체 데이터 합산하여 동별로 데이터 정렬하기
각 데이터 정규화 : 동별 거리 , 편의시설 수 , 가격
동네 추천순위 출력을 위한 점수 부여하기
Step3. 프로덕트 빌딩 및 시각화
사용자의 조건별 우선순위 입력
결과 데이터 중 Top 5개 동네 막대그래프로 시각화
Used Library
- selenium
- BeautifulSoup
- konlpy
- collections
- time
- pandas
- numpy
수집데이터
- 성남시 구별 검거율
- 성남시 단독 다가구 평당 평균가격(만원)
- 성남시 아파트 평당 평균가격(만원)
- 성남시 동별 동사무소에서 판교역까지 거리/시간
- 성남시 동별 공원 수
- 성남시 동별 의원 수
- 성남시 동별 마트 수
- 성남시 동별 편의점 수
작업 도중 발생한 이슈들
- 크롤링으로 데이터 수집 시 <em> 테그를 찾을 때 class_id 로 검색이 안되어서
부모테그 <div> 를 먼저 찾고 그 안의 인덱스로 접근하여 <em>테그를 찾아내었다. - 결측치들이 많은 동별 데이터들이 많아 결측치가 많아 데이터분석이 어려운 동은 삭제하였다.
총 44개의 동에서 26개의 동으로 축소했다. - 범죄 검거율 분석 중 치안율은 동별이 아니라 구별로 데이터가 있어서 동별로 차이를 두는것에
큰 의미가 없어 최종 합산 점수에 반영하지 않았다.
중요 알고리즘 소개
거리, 시간 데이터 크롤링
성남시 동사무소를 기준으로 판교역까지의 거리를 자동차 이동거리와 대중교통 이동거리 자동차 시간으로 나누고
그 거리 데이터를 받아오기 위해 네이버에 검색해서 자동으로 크롤링하는 알고리즘 구현
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import time
import pandas as pddef getTimeAndDis(url):
driver.get(url)
time.sleep(3)
driver.find_element_by_css_selector('button._ft_search').click()
time.sleep(3)
publicTime = driver.find_elements_by_class_name('info_detail')[0].find_elements_by_tag_name('em')[0]
publicTime = publicTime.text
car_button = driver.find_element_by_id('raa2')
car_button.click()
time.sleep(1)
driver.find_element_by_css_selector('button._ft_search').click()
time.sleep(1)
carTime = driver.find_elements_by_class_name('info_detail')[1].find_elements_by_tag_name('em')[0]
carDistance = driver.find_elements_by_class_name('info_detail')[1].find_elements_by_tag_name('em')[1]
carTime = carTime.text
carDistance = carDistance.text
return publicTime , carTime , carDistance검색이 안되서 에러가 발생하면 PublicTIme , carTIme carDistance 값들을 0,0,0 으로 대체
def addData():
for i in urlList:
try:
tempList = list(getTimeAndDis(i))
result.append(tempList)
except:
print("{}사이트에서 에러 발생".format(i))
temp1 = [0,0,0]
result.append(temp1)
pass
데이터 정규화 하기
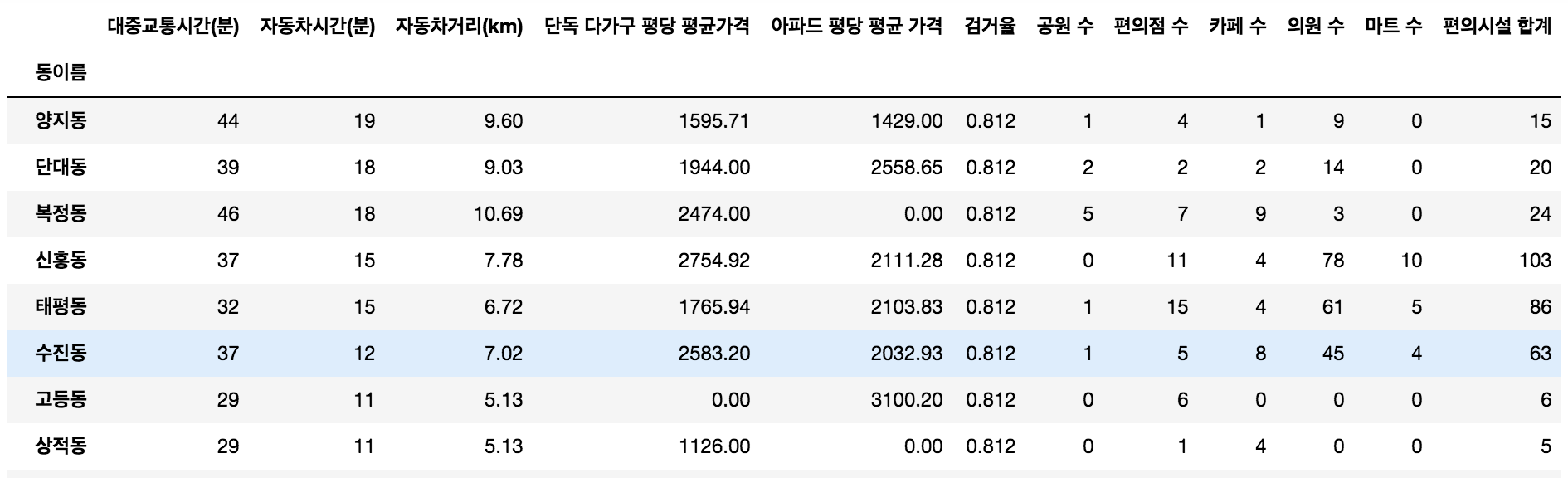
데이터를 최종합산 했지만 점수를 합산하고 비교하기에는 적절하지 않다. 그래서 이 데이터들을 정규화 해주어야 한다.
일단 첫 번째로 점수가 높을 수록 좋은 지역이기 때문에 짧을 수록 좋은 시간/거리를 전처리 해줘야한다.
그래서 현재값을 역수로 취해서 값을 바꿔주었다.
양지동의 경우 44를 1/44로 변경하여 높을 수록 값이 더 작아지도록 변경

아파트/주택 가격도 마찬가지로 저렴할 수 록 좋다고 판단하여 역수를 취해주었다.


min-max 정규화 하기
target_col = ['대중교통시간(분)', '자동차시간(분)', '자동차거리(km)', '단독 다가구 평당 평균가격', '아파드 평당 평균 가격','검거율','편의시설 합계']
weight_col = testData[target_col].max()
weight_col필요한 칼럼들만 target_col 에 넣고 그 칼럼들의 최대값을 weight_col 값의 넣는다.
crime_count_norm = testData[target_col]/weight_col
crime_count_norm["검거율"] = crime_count_norm["검거율"] / 10
crime_count_norm그리고 모든 값들을 최대값으로 나눠주어 제일 큰값이 1 이 되고 나머지는 0~1값을 가지게 된다.
최종점수 합산하기
점수를 합산하기 전에 나의 주거생활 기호에 맞게 아파트/주택과 가격 , 거리 , 편의시설 가중치를 설정한다.
carOrPublic = input("자동차를 타십니까 아니면 대중교통을 이용하십니까? ex(자동차 or 대중교통)")
houseOrApart = input("아파트에 살고싶습니까 아니면 주택에 살고싶으십니까? ex(아파트 or 주택)")
pricePersent = input("가격은 얼마만큼 중요합니까? ex(1~10)")
disScore = input("거리는 얼마만큼 중요합니까? ex(1~10)")
conven = input("편의시설은 얼만큼 중요합니까? ex(1~10)")예시)

pricePersent = float(pricePersent)
disScore = float(disScore)
conven = float(conven)그리고 계산하기 위해 실수형으로 형변환을 해준다.
점수 계산식
if carOrPublic=="자동차":
temp = pd.DataFrame()
temp['자동차시간(분)'] = df['자동차시간(분)']
temp['자동차거리(km)'] = df['자동차거리(km)']
temp['편의시설 합계'] = df['편의시설 합계']
temp['검거율'] = df['검거율']
temp['자동차시간(분)'] = temp['자동차시간(분)'] * ( 1 + (disScore / 10))
temp['자동차거리(km)'] = temp['자동차거리(km)'] * ( 1 + (disScore / 10))
temp['편의시설 합계'] = temp['편의시설 합계'] * ( 1 + (conven / 10))
elif carOrPublic=="대중교통":
temp = pd.DataFrame()
temp['대중교통시간(분)'] = df['대중교통시간(분)']
temp['검거율'] = df['검거율']
temp['편의시설 합계'] = df['편의시설 합계']
temp['대중교통시간(분)'] = temp['대중교통시간(분)'] * ( 1 + (disScore / 10))
temp['편의시설 합계'] = temp['편의시설 합계'] * ( 1 + (conven / 10))
if (carOrPublic=="자동차" and houseOrApart=="아파트"):
temp['아파드 평당 평균 가격'] = df["아파드 평당 평균 가격"]
temp['아파드 평당 평균 가격'] = temp['아파드 평당 평균 가격'] * ( 1 + (disScore / 10))
elif (carOrPublic=="자동차" and houseOrApart=="주택"):
temp["단독 다가구 평당 평균가격"] = df['단독 다가구 평당 평균가격']
temp['단독 다가구 평당 평균가격'] = temp['단독 다가구 평당 평균가격'] * ( 1 + (disScore / 10))
if (carOrPublic=="대중교통" and houseOrApart=="아파트"):
temp['아파드 평당 평균 가격'] = df["아파드 평당 평균 가격"]
temp['아파드 평당 평균 가격'] = temp['아파드 평당 평균 가격'] * ( 1 + (disScore / 10))
elif (carOrPublic=="대중교통" and houseOrApart=="주택"):
temp["단독 다가구 평당 평균가격"] = df['단독 다가구 평당 평균가격']
temp['단독 다가구 평당 평균가격'] = temp['단독 다가구 평당 평균가격'] * ( 1 + (disScore / 10))최종점수로 정렬
finalDf = pureData.sort_values(["최종점수"],ascending=False)
finalDf.head()
결론 :
자동차를 타고 주택에 거주를 희망하고 가격은 3 , 거리는 5 , 편의시설은 7 만큼 중요하면 성남시에서 서현동에 거주하는게
판교에 직장을 구할경우 가장 적합하다.
최종점수를 기준으로 막대그래프 시각화

'Project' 카테고리의 다른 글
| [Project] 주식, 최적의 분산투자를 위한 종목 추천 (1) | 2020.08.04 |
|---|