[Machine Learning] 단순선형회귀분석(Simple Linear Regression) 예제 ,pandas , numpy , plot
Machine Learning 머신러닝
먼저 회귀분석에 대해서 알아봅시다.
2020/04/22 - [데이터사이언스/머신러닝] - [기계학습] 4. 회귀분석 , 회귀계수 추정 , Matrix 미분 활용
[기계학습] 4. 회귀분석 , 회귀계수 추정 , Matrix 미분 활용
회귀분석이란? 회귀 분석에 들어가기 전에 먼저 지도 학습(Supervised Learnig)과 비지도 학습(Unsupervised Learning)에 대해서 알아봅시다. 2020/03/19 - [데이터 사이언스/머신러닝] - [기계학습] 2. 지도 학습.
acdongpgm.tistory.com
패키지 설치
|
import os
import pandas as pd
import numpy as np
import statsmodels.api as sm
|
예제 실습을 하기 위해서 pandas , numpy , statsmodels 패키지를 설치해야합니다.
|
#현재경로 확인
print(os.getcwd())
#데이터 불러오기
boston = pd.read_csv("./실습/part2_data/Boston_house.csv")
#데이터 불러오기 확인
print(boston.head())
#target 제외한 데이터만 뽑기
boston_data = boston.drop(['Target'],axis=1)
#데이터 통계 보기
print(boston_data.describe())
|
head() : 맨 위에 5개의 데이터만 추출해주는 함수.
drop() : 해당데이터를 제거하는 함수 , 뒤에 파라미터는 행이나 열이나를 판단
describe() : 데이터의 통계를 총갯수 , 평균, 4분위로 보여줌.

실습데이터 소개
|
타겟 데이터 |
CRIM / RM / LSTAT 세개의 변수로 각각 단순 선형 회귀 분석하기
|
#타겟 설정
target = boston[['Target']]
crim = boston[['CRIM']]
rm = boston[['RM']]
lstat = boston[['LSTAT']]
#crim변수에 상수항추가하기
crim1 = sm.add_constant(crim,has_constant="add")
#sm.OLS 적합시키기
model1 = sm.OLS(target,crim1)
fitted_model1 = model1.fit()
#summary 함수통해 결과 출력
print(fitted_model1.summary())
#회귀 계수 출력
print(fitted_model1.params)
|
add_constatnt(crim,has_constant="add")
statsmodels에는상수항 결합을 위한 add_constant 함수가 제공된다.
OLS
OLS(Ordinary Least Squares)는 가장 기본적인 결정론적 선형 회귀 방법으로 잔차제곱합(RSS: Residual Sum of Squares)를 최소화하는 가중치 벡터를 행렬 미분으로 구하는 방법이다.
우리가 사용하는 예측 모형은 다음과 같이 상수항이 결합된 선형 모형이다.

fit() : 모델을 적합시키고 피팅해주는 것이다.
summary() : 회귀분석의 결과를 출력해주는 함수

|
#회귀 계수 x 데이터(x)
np.dot(crim1,fitted_model1.params)
pred1 = fitted_model1.predict()
#직접구한 yhat과 predict 함수를 통해 구한 yhat차이
print(np.dot(crim1,fitted_model1.params) - pred1)
|
회귀 계수와 데이터의 행렬을 곱한 값들(직선)을 통해 우리가 추정하는 값(yhat)을 알아낼 수 있다.
params() : 회귀계수를 출력해주는 함수
predict() : yhat 을 구해주는 함수로 np.dot(crim1,fitted_model1.params)와 같다.
실제로 np.dot(crim1,fitted_model1.params) - pred1 를 해보면 모든 값이 0 인 행렬이 나온다.
* 차이가 없다는 뜻
|
#적합시킨 직선 시각화
import matplotlib.pyplot as plt
plt.yticks(fontname = "Arial")
plt.scatter(crim,target,label="data")
plt.plot(crim,pred1,label="result")
plt.legend()
plt.show()
|



잔차의 합 계산해보기
|
np.sum(fitted_model1.resid)cs
|

잔차의 합은 0 에 가깝게 나온다고 볼 수 있다.
Why?
잔차가 최소한으로 하는 직선(선형회귀) OLS 를 적합시켰기 때문에
위와 동일하게 rm 변수와 lstat 변수로 각각 단순선형회귀분석 결과보기
|
#rm 모델결과출력
fitted_model2.summary()
#lstat 모델결과출력
fitted_model3.summary()
# 각각 yhat_예측하기
pred2 = fitted_model2.predict(rm1)
pred3 = fitted_model3.predict(lstat1)
#rm 시각화
plt.scatter(rm,target,label="data")
plt.plot(rm,pred2,label="result")
plt.legend()
plt.show()cs
|

|
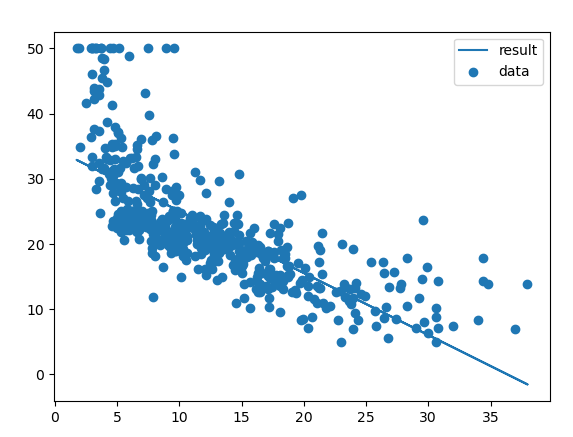
#lstat 시각화
plt.scatter(lstat,target,label="data")
plt.plot(lstat,pred3,label="result")
plt.legend()
plt.show()cs
|


|
# 세 모델의 residual 비교
fitted_model1.resid.plot(label="crim")
fitted_model2.resid.plot(label="rm")
fitted_model3.resid.plot(label="lstat")
plt.legend()
plt.show()
|
